
3. modul: Webarchívum kialakítása Linux szerveren
Bevezető gondolatok
Webhelyek tömeges lementéséhez és metaadatolásához, az archivált tartalmak visszanézéséhez, a bennük való kereséshez és adatbányászathoz, statisztikák és grafikonok készítéséhez, illetve az egész folyamat menedzseléséhez az internetes tartalmak megőrzésével foglalkozó intézmények és szervezetek különféle szoftvereket fejlesztettek ki az elmúlt évtizedekben. Ezek egy része nyílt forráskódú (open source), tehát ingyenesen letölthető és igény szerint átalakítható, más részük az adott webarchívum számára készült, de esetleg egyedi megállapodások alapján használható és adaptálható másoknak is. Ezen szoftverek többnyire Linux-alapú szervergépekre íródtak és íródnak ma is, jellemzően Java, PHP, Perl, Python vagy C++ nyelveken. Az Internet Archive és az IIPC koordináló szerepének köszönhetően fokozatosan kialakultak olyan szabványosnak tekinthető megoldások, mint az ARC, majd ebből a WARC tárolási formátum, illetve a CDX index formátum, és emiatt ezek a különféle helyeken fejlesztett programok képesek együttműködni, adatokat cserélni egymással, így – kellő informatikai tudással – összerakható belőlük egy, az adott webarchívum igényeit kielégítő rendszer. „Kulcsrakész”, minden funkcióra azonnali megoldást kínáló ingyenes webarchiváló rendszer tehát nincsen, és mivel az egyes részfeladatokra alkalmas programok gyakran 1-2 személyes projektek keretében készülnek, ezért ezek sem mindig kiforrott és folyamatosan karbantartott szoftverek. A webarchívumok számára hasznos eszközökről az IIPC honlapján és néhány további weboldalon találunk listákat és ismertetéseket. [wiki szócikk]
Célok, megszerezhető kompetenciák:
A modul célja, hogy bemutasson néhány olyan nyílt forráskódú, vagy legalább ingyenes szoftvert, amelyekből összerakható egy komolyabb, Linux szerverre alapozott intézményi webarchiváló rendszer. Ismerteti továbbá a lementett webhelyek minőségellenőrzésének és metaadatolásának ajánlott módszertanát. A tananyag elsajátítása segít abban, hogy egy közgyűjteményi szakember – informatikus bevonásával – képes legyen megtervezni egy archiváló rendszert és annak munkafolyamatait, vagy bekapcsolódni egy már létező archívum építésébe.
Szükséges eszközök, források:
Asztali számítógép vagy laptop internet kapcsolattal és webböngészővel.
Feldolgozási idő:
8×45 perc
Témakörök:
Ajánlott irodalom:
Drótos László - Németh Márton: Egyedi mentésekre szolgáló webarchiváló szoftverek
In: Könyv, Könyvtár, Könyvtáros, 2020. (29. évf.), 12. sz.
http://ki2.oszk.hu/3k/2020/12/egyedi-mentesekre-szolgalo-webarchivalo-szoftverek/Ilácsa Szabina: Webhelyek metaadatolási problémái
In: Könyvtári Figyelő, 2020. (66. évf.), 1. sz.
https://epa.oszk.hu/00100/00143/00359/pdf/EPA00143_konyvtari_figyelo_2020_01_074-082.pdf
1. Archiváló és megjelenítő szoftverek
1.1. A Heritrix aratószoftver
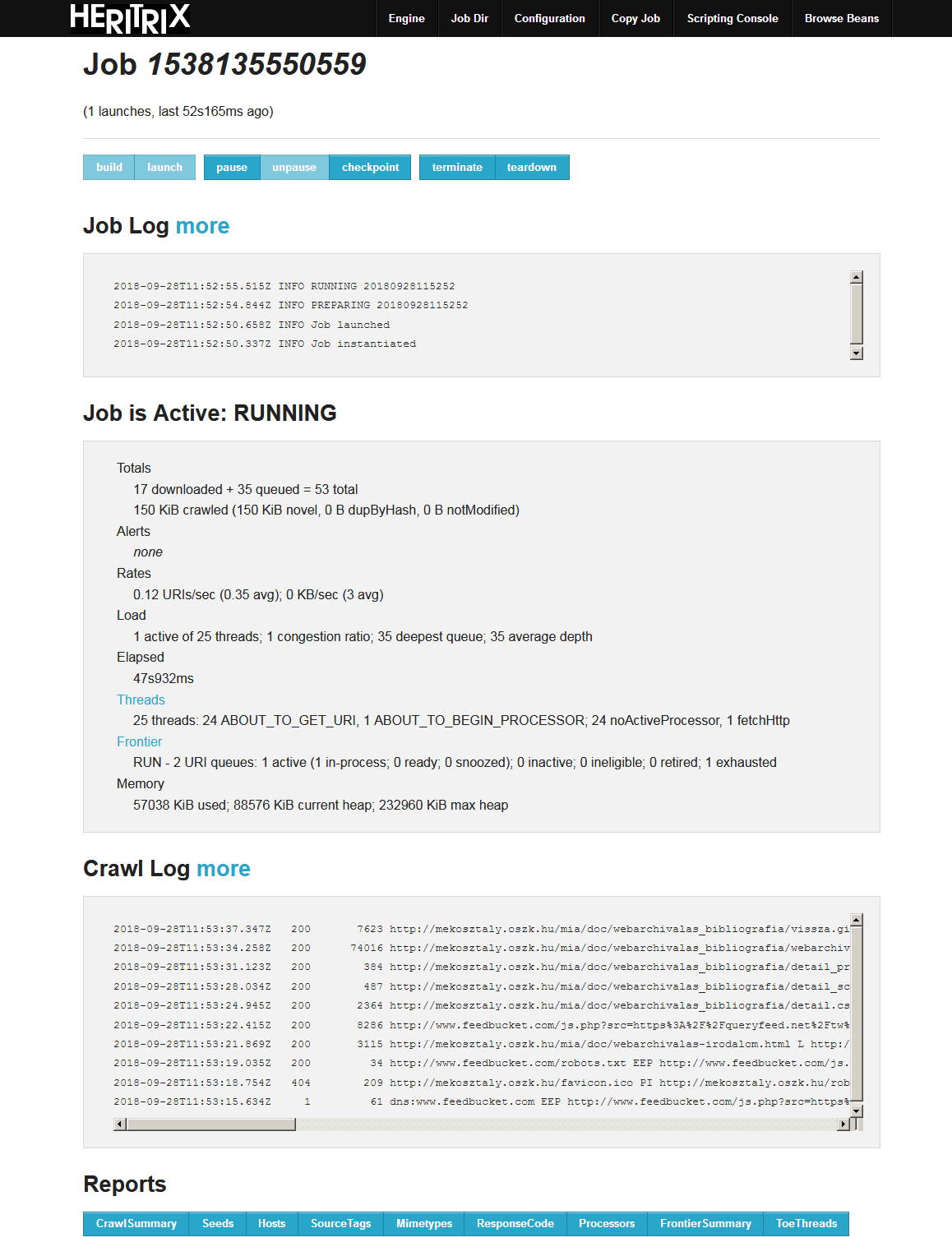
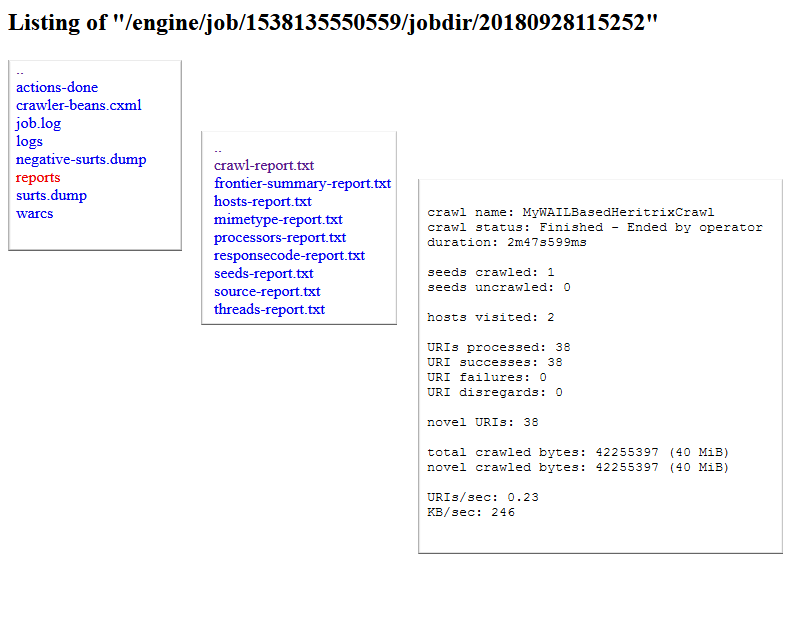
A Heritrix [wiki szócikk] az Internet Archive által fejlesztett szoftveres robot [crawler][1], ami egy megadott kezdő URL címtől [seed][2] elindulva letölti az adott címen található weboldalt és elkezdi követni a benne levő linkeket, újabb és újabb oldalakat és egyéb állományokat töltve le. A robot viselkedését egy szöveges konfigurációs fájllal szabályozhatjuk, amelyben rengeteg beállítási lehetőség van. A program működése egy böngészőben megnyitható adminisztrációs felületen keresztül is menedzselhető. Ugyanitt láthatók az egyes job-ok, vagyis aratási feladatok előrehaladása <3.1.1_heritrix_admin.png> és a feladatok befejezésekor lezárt log és report, vagyis napló és jelentés fájlok is. <3.1.1_heritrix_report.png> A Heritrix egy moduláris felépítésű szoftver, amely igény szerint további modulokkal bővíthető. Az aratás menetét a crawl frontier [wiki szócikk][3] nevű rész irányítja a konfigurációs paraméterek figyelembe vételével. De kapcsolható hozzá egy ún. deduplikációs [wiki szócikk][4] modul is, amivel azt lehet megoldani, hogy egy webhely ismételt aratásakor már csak a korábbi futás óta megváltozott vagy az új fájlokat mentse el a robot a WARC [wiki szócikk][5] konténerekbe, amivel jelentős tárhely-megtakarítás érhető el. (A Heritrix régi verziói a WARC-nál egyszerűbb ARC [wiki szócikk][6] formátumot használták tárolásra, ami még jelenleg is választható opció, sőt akár fájlrendszerbe, alkönyvtárakba is tud menteni, akárcsak a HTTrack.) A Heritrix számos nagy, pl. nemzeti webarchívumnál az elsődleges crawler, és összeépítették olyan rendszerekkel, mint a korábban ismertetett WAIL, illetve a továbbiakban bemutatásra kerülő WCT és NAS. Bár 2003 óta rengeteget fejlődött, kezd eljárni felette az idő, mivel alapvetően a hagyományos web felderítésére és begyűjtésére készült, és a modern, dinamikus, interaktív, médiagazdag, adatbázisalapú, webkettes szolgáltatásokkal kevésbé jól boldogul, ezeket csak töredékesen vagy egyáltalán nem tudja menteni. Ezt a problémát különféle kiegészítőkkel vagy másfajta, böngésző-alapú crawler-ek fejlesztésével igyekeznek megoldani a webarchiválással foglalkozó szakemberek.
{kind=link}
{kind=link}
Ajánlott források: 1. Heritrix wiki, 2. Jurányi Zsolt: Heritrix 3 konfig receptkönyv
Az előadó prezentációja: Vitéz Gábor: Az arató és a megjelenítő szoftverekről
1.2. A Brozzler aratószoftver
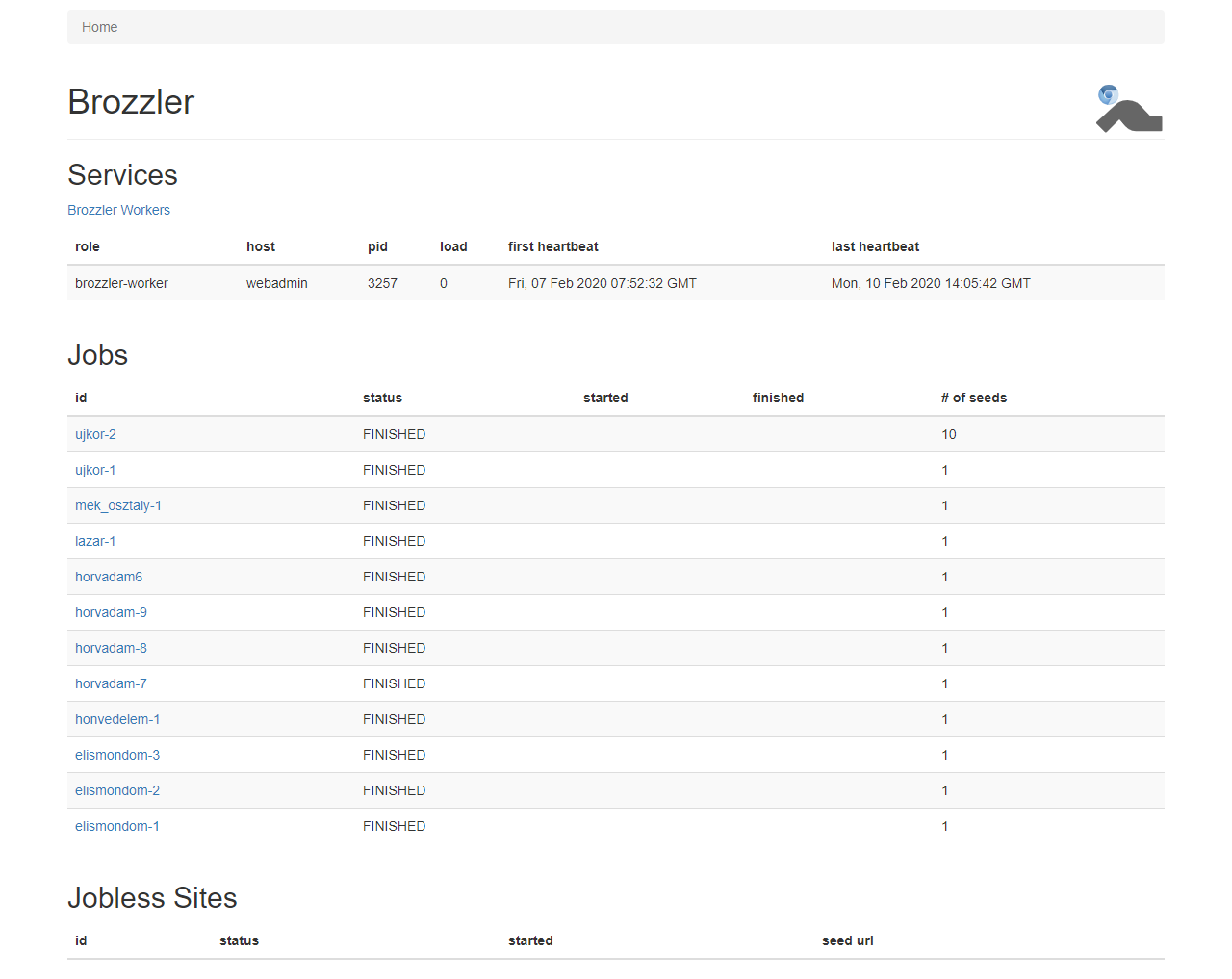
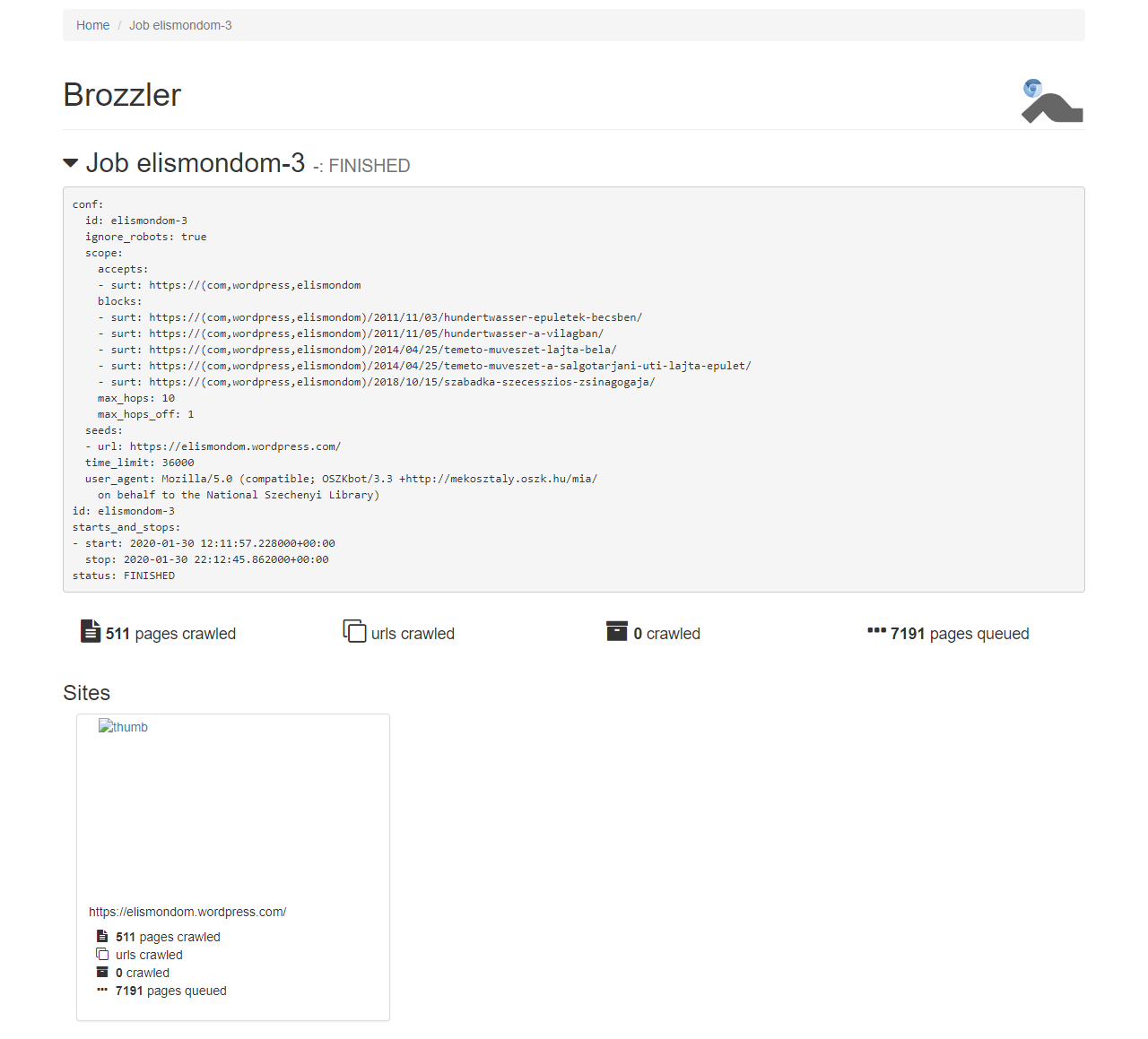
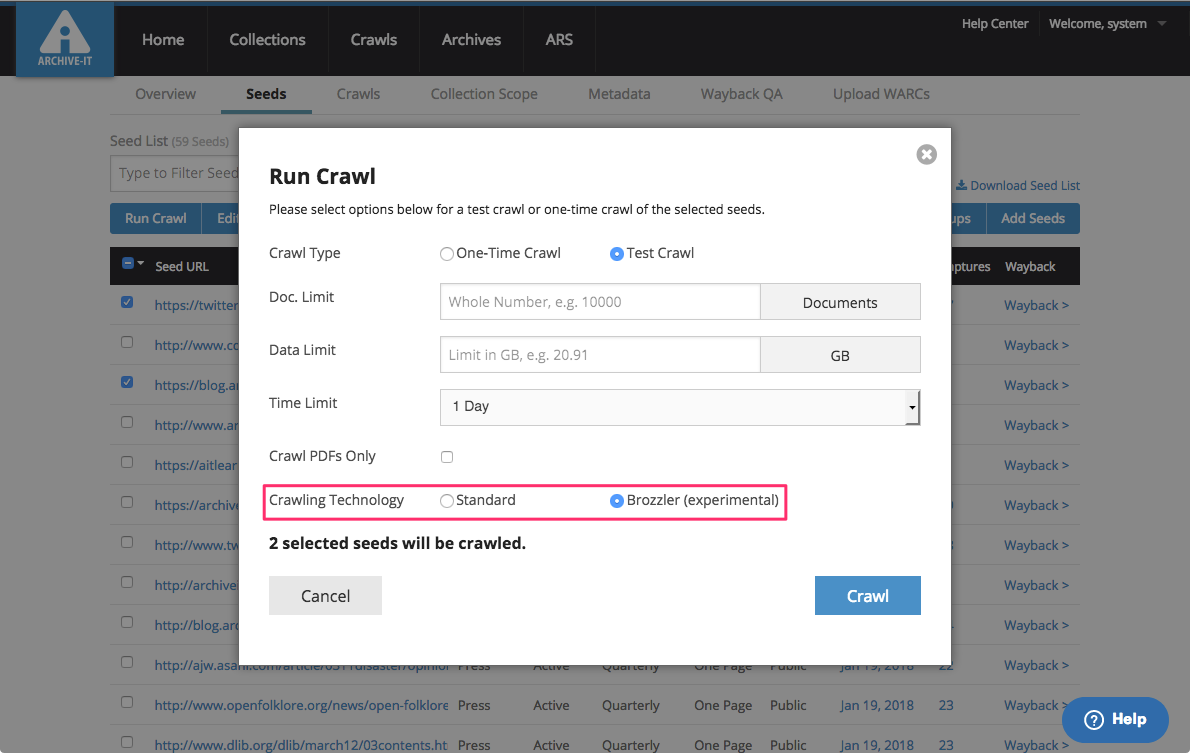
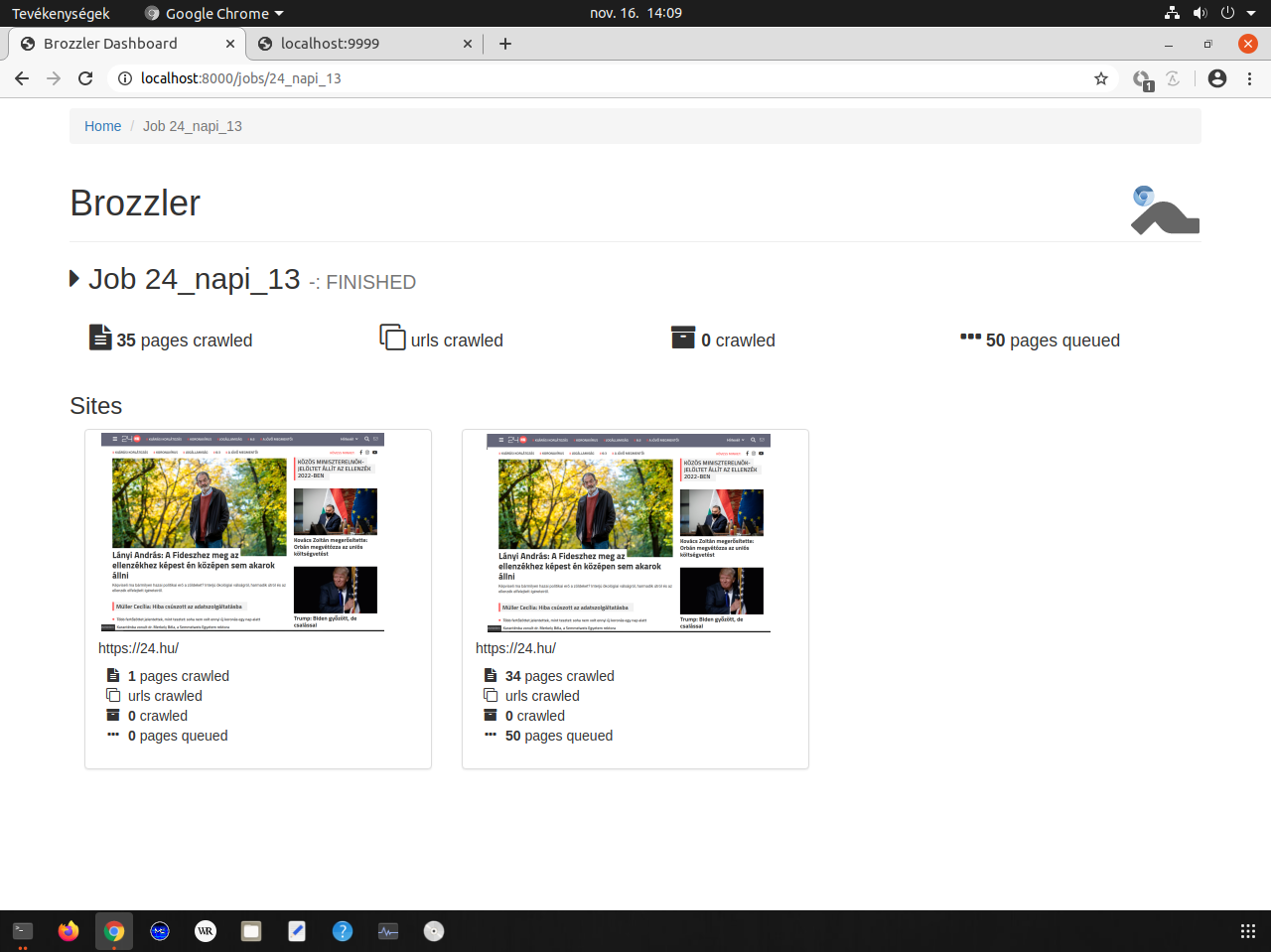
A Brozzler [wiki szócikk] szintén az Internet Archive fejlesztése, melyet 2016-ban mutattak be az IIPC éves konferenciáján, és amint a neve is jelzi, egy böngésző és egy robot (browser + crawler) együttműködésére épül. A Chrome megjelenítő modulját hívja meg, de annak felhasználói felülete nélkül, ún. headless [wiki szócikk][7] módban és egy Youtube videókhoz kifejlesztett letöltő programot is használ. Amellett, hogy az adott weboldalt és annak médiaelemeit WARC formátumban elmenti, ugyanúgy követi az oldalon talált linkeket, mint a Heritrix robotja, de a böngészőn keresztül való mentésnek köszönhetően jobban boldogul az olyan interaktív, JavaScript, AJAX, Flash stb. programkódokat tartalmazó, dinamikusan generált oldalakból álló, illetve média-gazdag [RIA][8] webhelyekkel, mint amilyenek a webkettes, közösségi platformok (pl. Instagram, Facebook, Youtube). Önálló felhasználói felület még nincsen hozzá, csak egy „műszerfal”, ahol a futó és a befejezett aratási feladatok látszanak. <3.1.2_brozzler_dashboard1.png> <3.1.2_brozzler_dashboard2.png> A job-ok paramétereit egy konfigurációs fájlban lehet beállítani. Ebben megadhatunk az egész aratásra, valamint csak egyes webhelyekre (seed címekre) vonatkozó korlátokat és technikai metaadatokat. A seed-szintű adatok közt lehet egy username és egy password is, amiket a robot automatikusan beír olyankor, ha egy bejelentkező képernyőnek tűnő űrlapot talál, így a nem publikus vagy csak regisztrált felhasználók számára elérhető webes tartalmak mentésére is alkalmas, amennyiben az archiváló személynek/intézménynek van ezekhez hozzáférése. A Brozzlerrel való aratást már beépítették az Archive-It szolgáltatásba <3.1.2_brozzler_archive-it.png> és egyes nemzeti könyvtárak is kísérleteznek vele. 2020 ősze óta az OSZK is használja hírportálok napi szintű mentésére. <3.1.2_brozzler_oszk.png>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ajánlott források: 1. Sylvie Rollason-Cass: What is Brozzler?, 2. Noah Levitt: brozzler
1.3. Az ArchiveBox archiváló szoftver
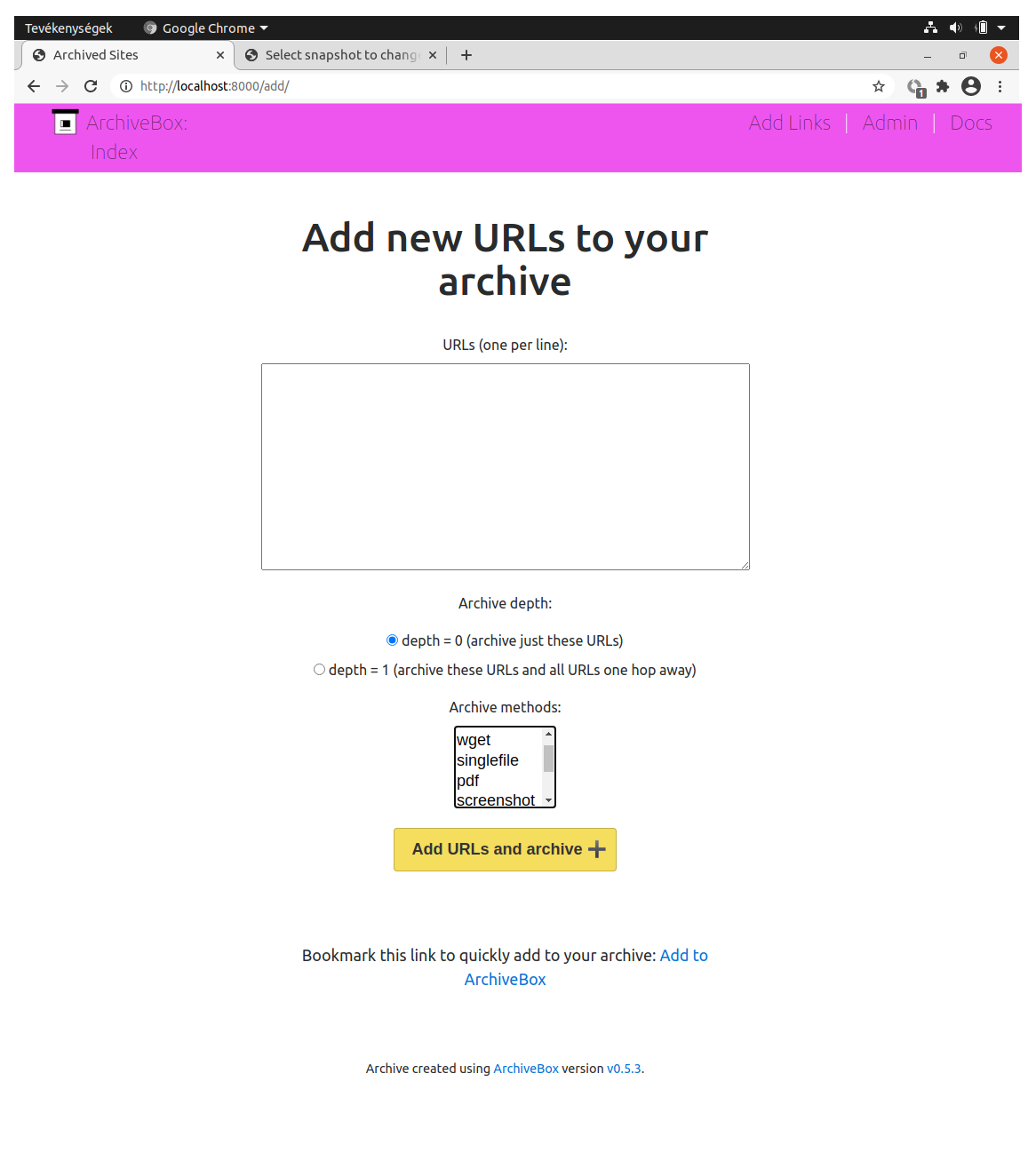
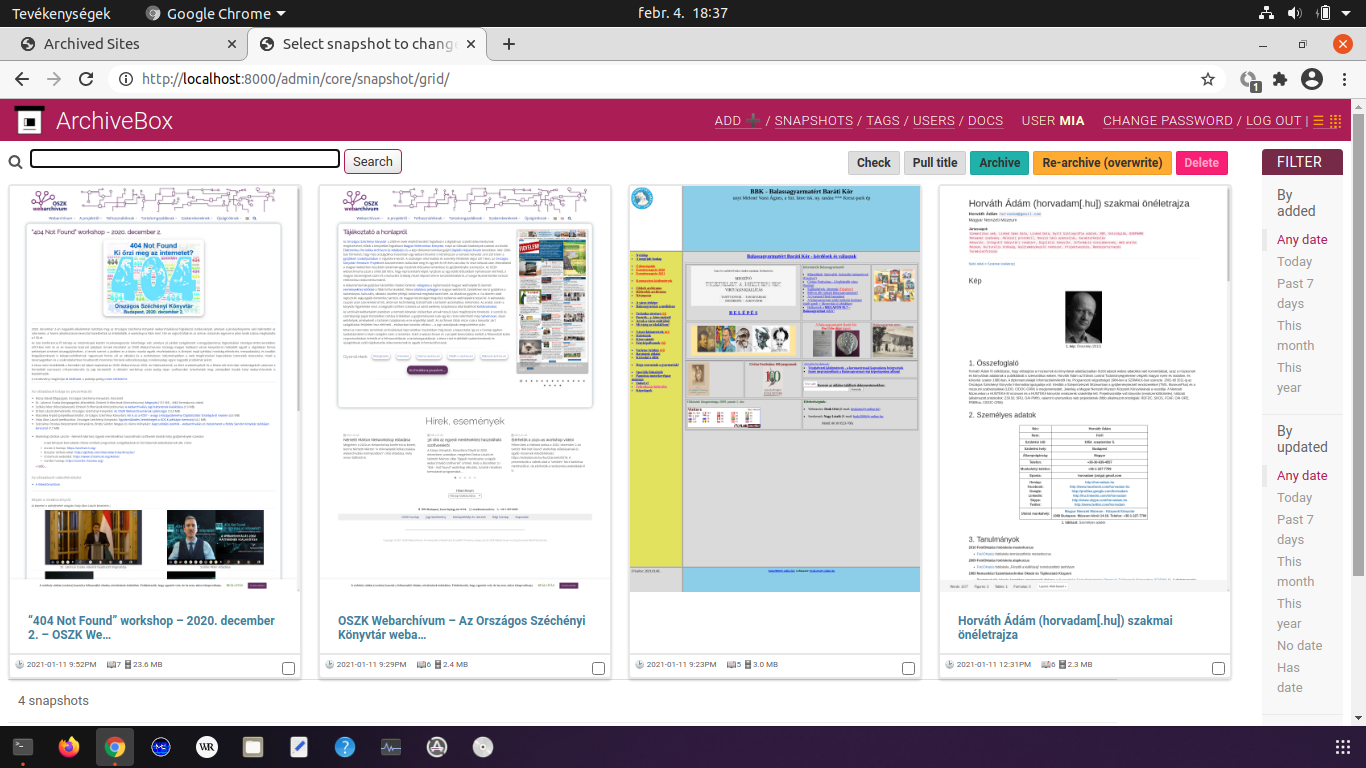
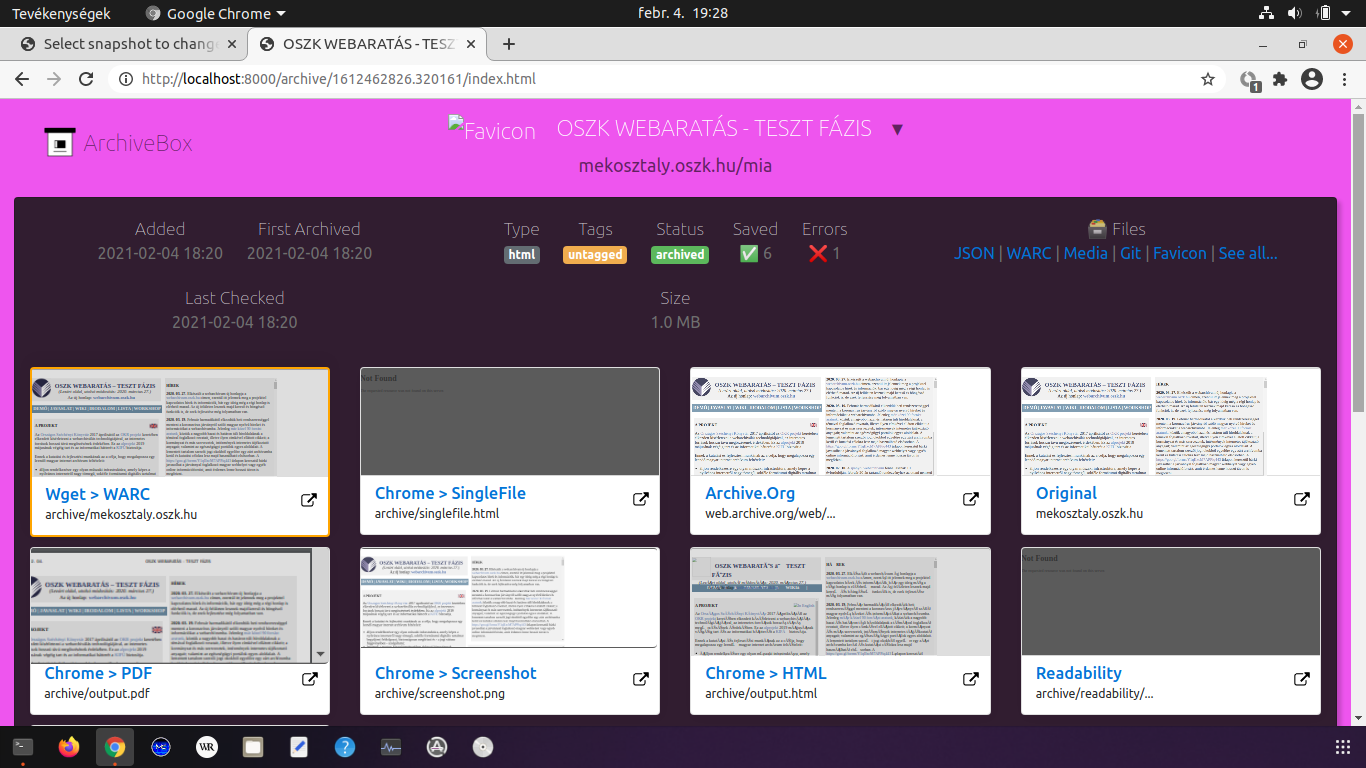
Az ArchiveBox [wiki szócikk] egy kanadai programozó által 2017 óta fejlesztett archiváló eszköz, amely a wget [wiki szócikk] nevű aratószoftvert, a Brozzlerhez hasonlóan headless módban futtatott Chrome motort és a youtube-dl [wiki szócikk] videóletöltőt integrálja egy rendszerbe. A Python nyelven írt open-source szoftver többféle formátumba is tud menteni (warc, fájlrendszer, egyetlen HTML fájl, PNG, PDF) és külön is letölthetők a megadott weboldal egyes elemei (title, favicon, response header, médiafájlok), illetve az oldal automatikusan generált metaadatai, sőt az archive.org szerverre is elmenthetünk egy másolatot. A seed URL címek megadhatók egy szövegfájlban, de könyvjelzőkből, böngészési előzményekből és RSS feed-ekből is ki tudja őket gyűjteni a program. Továbbá képes olyan szoftver-repozitóriumok egyes részeinek klónozására is, mint a github, a bitbucket, vagy a gitlab. A távlati fejlesztési tervek között szerepel a PyWb-vel [wiki szócikk] való archiválás és megjelenítés beépítése, valamint a felhasználó által definiálható scriptek futtatása a böngészőben, ami az emberi interaktivitást igénylő webkettes platformokról való automatikus mentésekhez lenne nagyon hasznos. Az ArchiveBox valamennyi funkciója csak parancsmódban érhető el, de van hozzá egy webes adminisztrátori felület is, amivel egyszerűbb aratások paraméterezhetők és elindíthatók, <3.1.3_archivebox1.png> valamint visszanézhetők a korábbi mentések. <3.1.3_archivebox2.png> <3.1.3_archivebox3.png>
{kind=link}
{kind=link}
{kind=link}
Ajánlott források: 1. Nick Sweeting: Archiving the Internet Before it All Rots Away (videó), 2. ArchiveBox Documentation
1.4. Az Open Wayback és a PyWb megjelenítő
A Open
Wayback (OWB) [wiki szócikk]
az Internet Archive honlapján található Wayback Machine
[wiki szócikk]
szolgáltatás programjának nyílt forráskódú átirata,
melyet az IIPC is támogat. Egy megjelenítő eszköz, amivel –
egy ún. CDX indexfájl [wiki szócikk][9]
generálása után – a WARC fájlokban tárolt archivált weboldalak egy
böngészőbe betölthetők és úgy nézegethetők ezek múltbeli állapotai, mintha
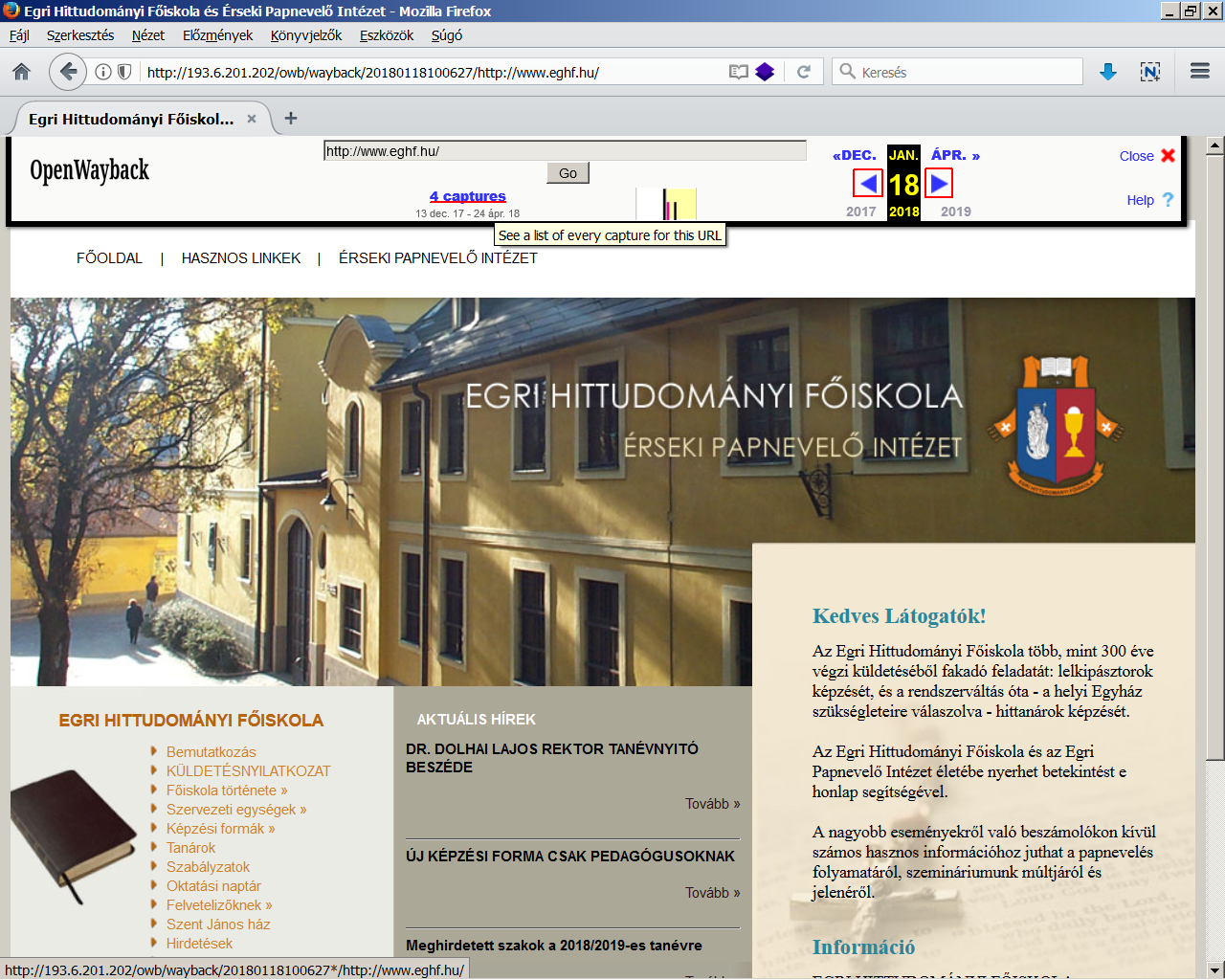
az élő weben lépegetnénk. A Wayback egyfajta időgépként használható: először
meg kell adnunk a bennünket érdeklő weboldal eredeti URL címét, majd egy
naptárfelületen megjelennek a róla készült mentések dátumai. Ezek egyikét
kiválasztva betöltődik az adott mentés és felette a Wayback (bezárható)
fejléce, benne egy időskálával, amivel átmehetünk a további mentésekre.
<3.1.4_owb1.png>
A lementett weboldalakon a linkeket követve mindaddig tudunk navigálni,
amíg el nem érünk egy olyan pontra, ami már nincsen meg a webarchívumban.
<3.1.3_owb.mp4>
Egy hiperhivatkozásra kattintva a szoftver a kiinduló dátumhoz időben legközelebbi
mentést keresi ki az archívumból, de ha sokat kattintgatunk, akkor előfordulhat,
hogy már akár évekkel korábbi vagy későbbi állapotú oldalakat látunk ahhoz
képest, mint amiből elindultunk [temporal
drift][10].
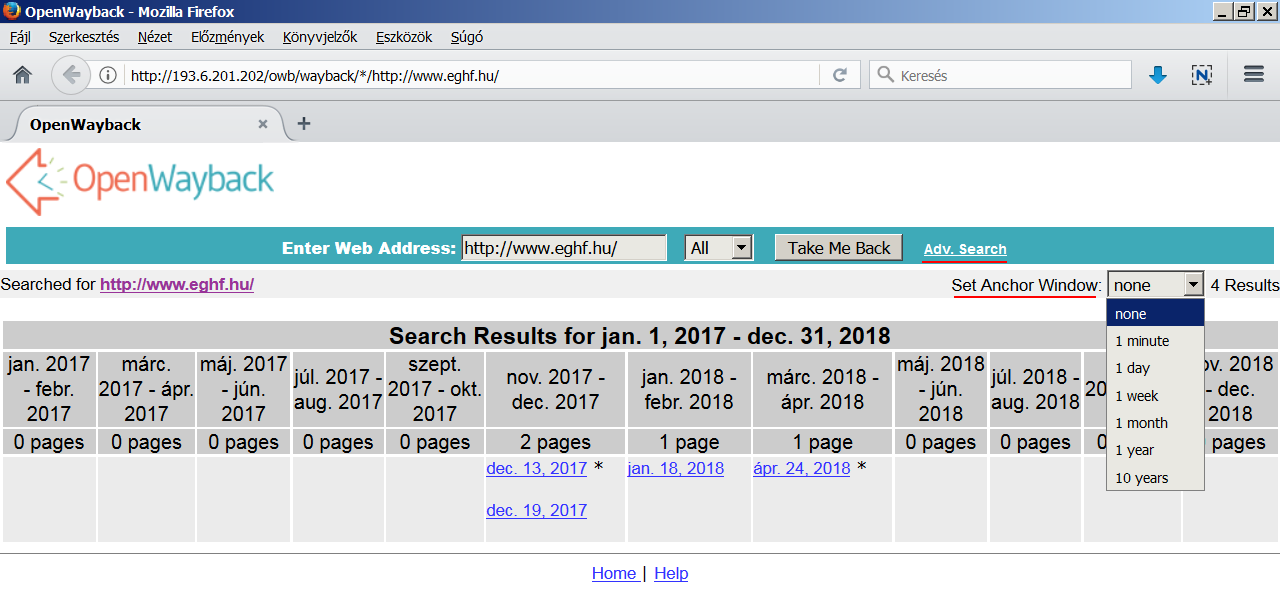
(Ezt az időbeli sodródást korábban a kiinduló naptárfelületen levő Set
Anchor Window opcióval csökkenthettük, de 2019-ben sajnos kikerült ez
a lehetőség az OWB újabb verzióiból.) <3.1.4_owb2.png>
További tévedésekhez vezethet, ha egy weboldalba olyan külső médiatartalom
van beágyazva, amely az élő webről jön, így előfordulhat, hogy mondjuk egy
tíz évvel ezelőtti híroldalon a mai időjárás-jelentés jelenik meg [live
web leakage][11].
(Ez utóbbi hibajelenséget a Wayback proxy módú használatával lehet
kiküszöbölni, mert ilyenkor a felhasználó böngészője minden kérést a Wayback
proxy szerverének küld, így azok el sem jutnak az eredeti webszerverig.)
A programnak van egy Adv. Search nevű keresőűrlapja is, de metaadat
szintű vagy teljes szövegű keresést ezt sem biztosít, csupán annyival több,
hogy a dátum mellett az URL elejére is rá lehet keresni, így nem kell tudnunk
a weboldal pontos címét ahhoz, hogy megtaláljuk az archívumban. Ugyanilyen
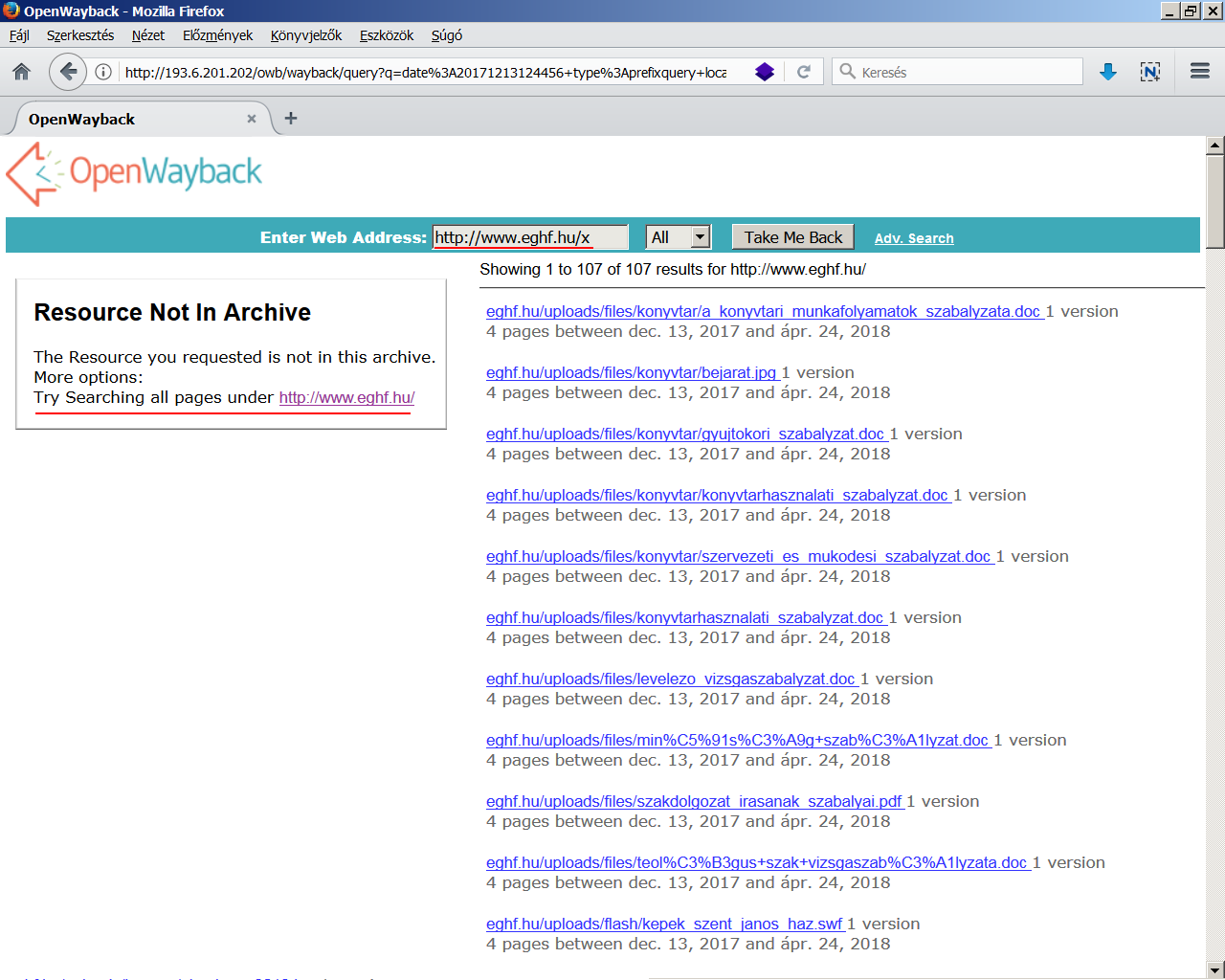
fájllistát kapunk olyankor is, ha egy hibás URL címet írunk az Enter
Web Address sorba, vagy egy olyan linkre kattintunk, amelyhez
tartozó fájl nincs meg az archívumban. Ilyenkor a Wayback kiír egy Resource
Not In Archive hibaüzenetet, de felajánlja annak a lehetőségét, hogy
megnézzük, milyen lementett fájlok vannak az adott alkönyvtár alatt. <3.1.4_owb3.png>
Az OWB-hez hasonló, de egyszerűbb naptári felülettel és fejléccel rendelkező
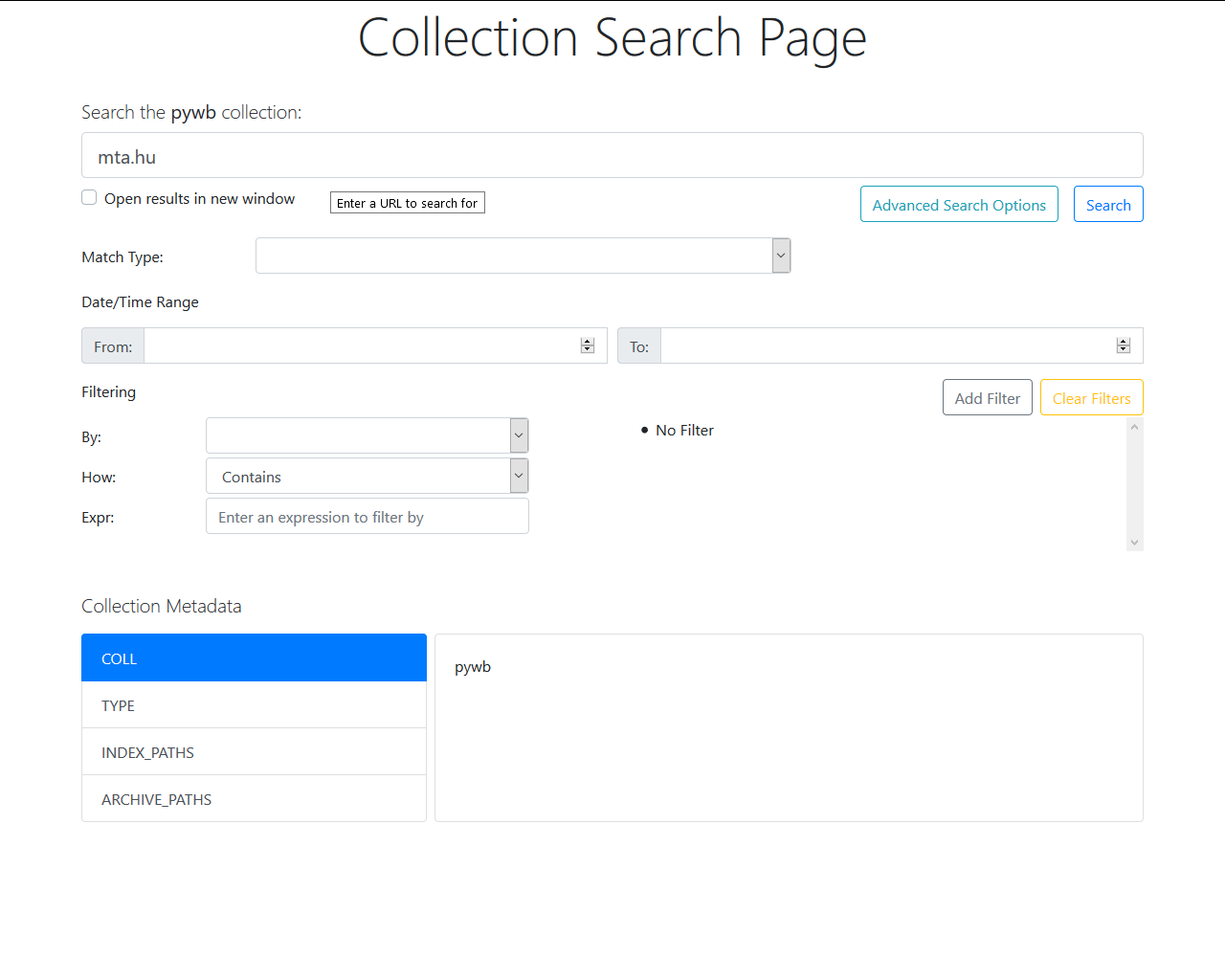
WARC megjelenítő eszköz a Python nyelven írt PyWb [wiki szócikk],
melyet például a WAIL is használ, és a Webrecorderhez hasonló, de csak parancsmódban
futtatható record funkciója is van, vagyis WARC fájlba tudja menteni
a böngészőben megnézett oldalakat. Az IIPC 2020-as döntése szerint az OWB
helyett ezentúl a PyWb fejlesztését fogják támogatni. <3.1.4_pywb.png>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ajánlott források: 1. OpenWayback wiki, 2. OSZK-s webhelyek archívuma
1.5. Virtuális gép
Az OSZK Webarchiválási Osztályán 2020 nyarán tesztelési és oktatási célból összeállítottunk egy virtuális gépet, amivel Windows alatt lehet Ubuntu Linux rendszert futtatni, s így olyan archiváló szoftvereket is ki lehet próbálni, amelyek Windowsban nem, vagy nem elég hatékonyan működnek. A virtuális gép egyetlen 40 GB-os fájlban tölthető le egy felhőtárhelyről, így egy komplett, előzetesen beállított tesztkörnyezetet tudunk az érdeklődők részére rendelkezésre bocsátani, akiknek elég csak az ingyenes Oracle VirtualBox-ot feltenni, majd hozzáadni ahhoz ezt a lementett fájlt. A gépen a Linux alaprendszeren kívül jelenleg a következő szoftverek vannak feltelepítve: Brozzler, Webrecorder Desktop (ez Linuxon sokkal gyorsabb, mint a Windows alatti változata), ArchiveBox, a PyWb, az ArchiveWeb.Page és a ReplayWeb.Page, valamint a Brozzler által használt Python környezet és a RethinkDB adatbáziskezelő. Ezeken kívül a Chrome és a Firefox böngészőket, a Midnight Commander fájlkezelőt és néhány más hasznos segédprogramot is kitettünk az asztalra. <3.1.5_mia_vm.png> Akit érdekel ez a virtuális gép, az írjon a mia@mek.oszk.hu e- mail-címre, és megadjuk a letöltési helyet meg a rendszergazdai jelszót, illetve segítünk a beüzemelésben.
{kind=link}
2. A WCT és a NAS keretrendszer
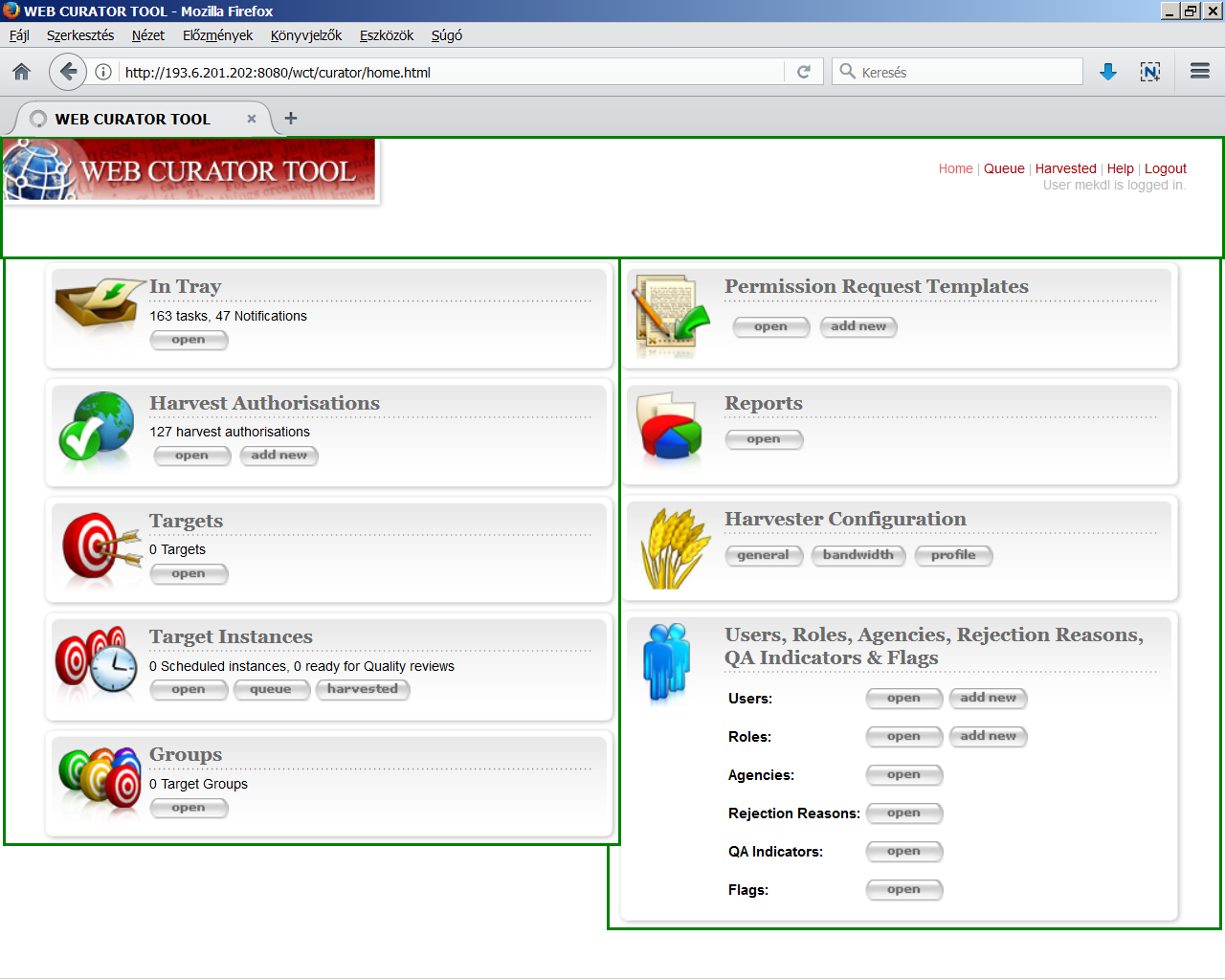
2.1. A Web Curator Tool keretrendszer
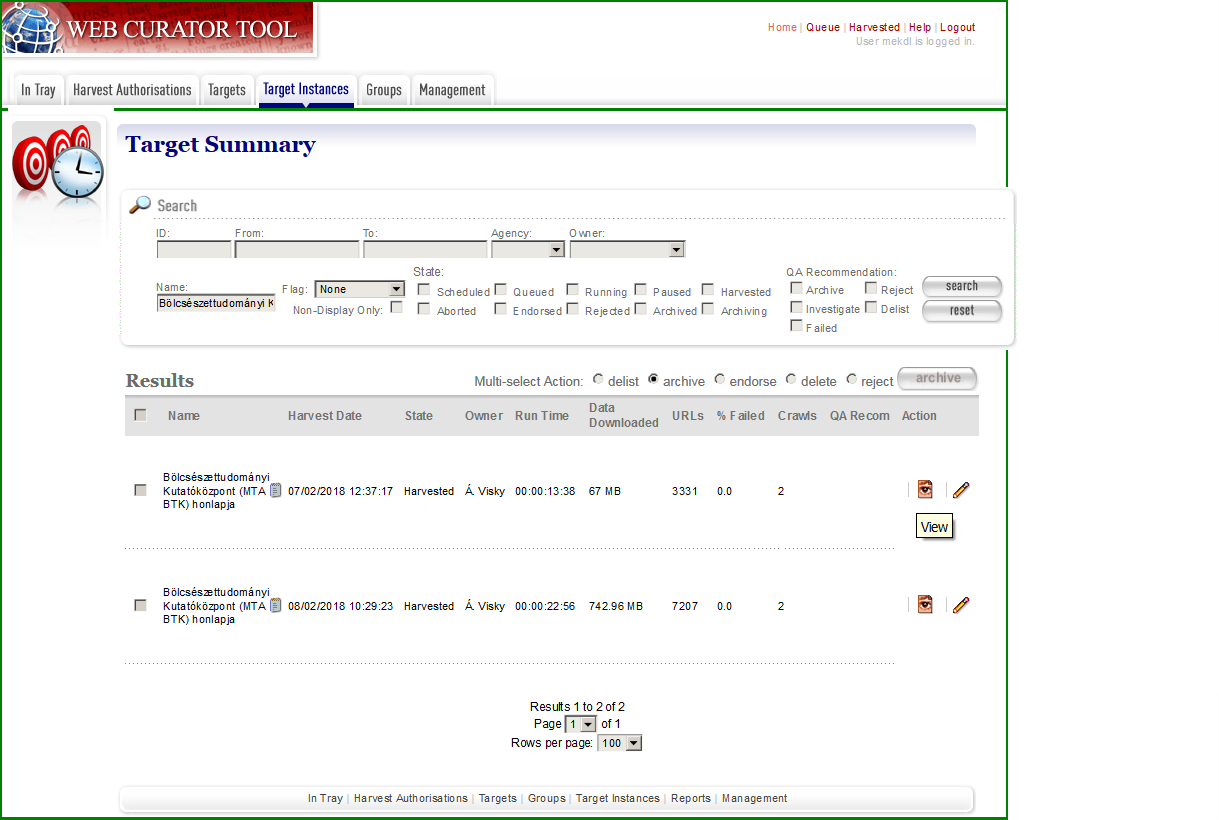
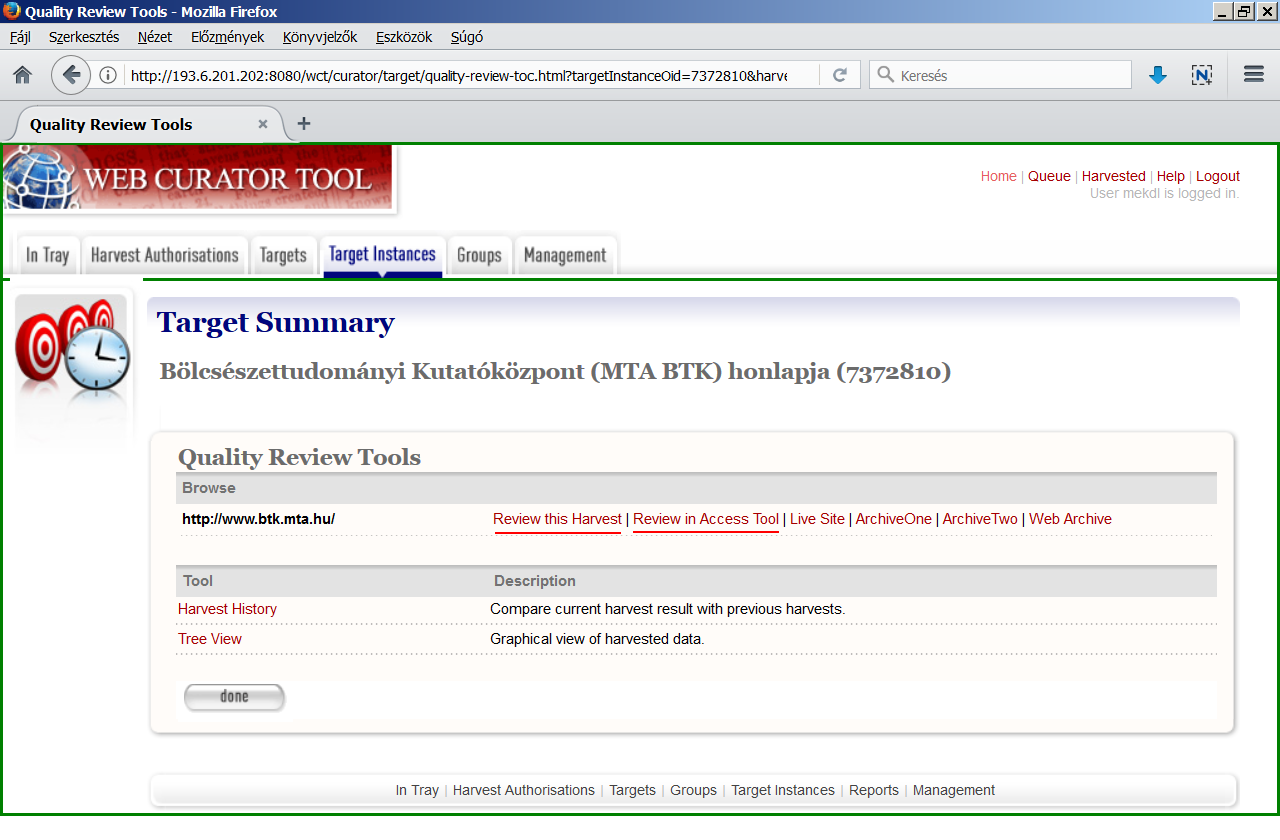
A Web Curator Tool [wiki szócikk] a Heritrix köré épített, böngészőből használható adminisztrátori és munkafolyamat-nyilvántartó open source szoftver, melynek fejlesztése 2006-ban indult el a British Library-val való együttműködés keretében az új-zélandi nemzeti könyvtárban. <3.2.1_wct1.png> Nyilvántarthatjuk vele a megőrzésre kiválasztott webhelyeket, [target][12] alapszintű leíró metaadatokat adhatunk hozzájuk és tematikus vagy egyéb csoportokba is besorolhatjuk őket, kezelhetjük az archiválásra és a szolgáltatásra vonatkozó engedélykéréseket, paraméterezhetjük az egyes aratásokat és azok ütemezését is beállíthatjuk, [harvest optimisation][13] <3.2.1_wct2.png> majd pedig ellenőrizhetjük a lementett verziókat [instance][14] <3.2.1_wct3.png> a saját megjelenítője vagy az Open Wayback segítségével. <3.2.1_wct4.png> Mivel minden művelet jogosultsághoz kötött és a regisztrált felhasználók különböző jogosultságokkal rendelkező csoportokba sorolhatók, így különösen alkalmas olyan gyűjtemények építésére, ahol több intézmény vagy szervezeti egység munkamegosztásban végzi az archiválást. <3.2.1_wct.mp4> Nyilvános szolgáltatófelület nincs hozzá és nem segíti a WARC fájlok hosszú távú digitális raktározását sem, ezért ezekhez a részfeladatokhoz valamilyen helyi megoldás, fejlesztés kell. További hátránya volt, hogy a 2010-es években a frissítése lelassult, ezért sokáig csak a Heritrix régebbi verzióját támogatta. Szerencsére 2018-ban újraindult a fejlesztése a holland királyi könyvtárral együttműködésben, így várhatóan több nemzeti webarchívumnál ezt a keretrendszert használják majd továbbra is. 2021 elején megjelent a WCT 3.0-ás verziója, amelyhez egy előre bekonfigurált virtuális gép is tartozik. Ezt a Windows alatt is használható Oracle VM VirtualBox-ban lehet futtatni.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ajánlott források: 1. Web Curator Tool Documentation, 2. Philip Beresford: Web Curator Tool, 3. WCT 3.0 Release
2.2. A NetarchiveSuite keretrendszer
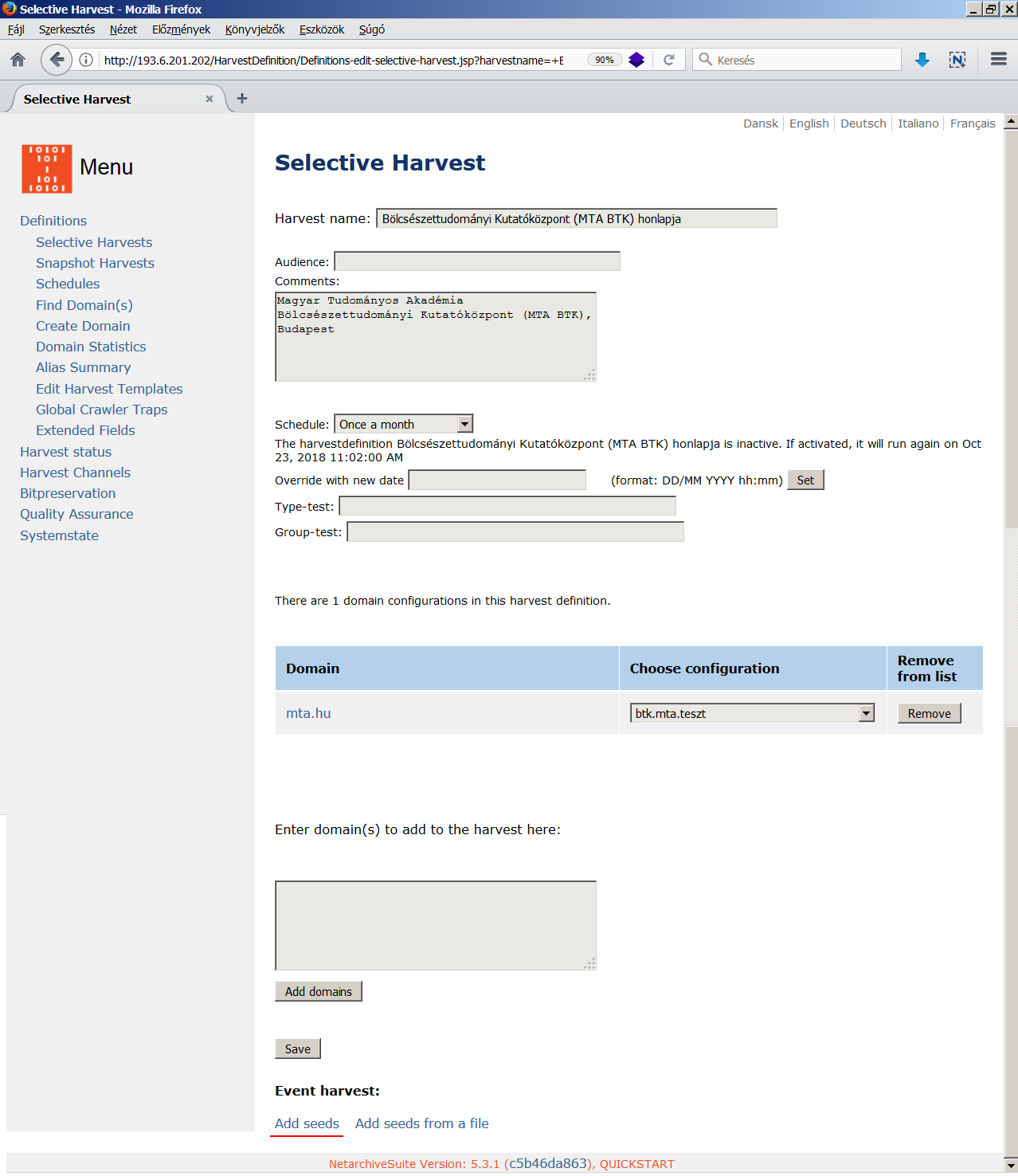
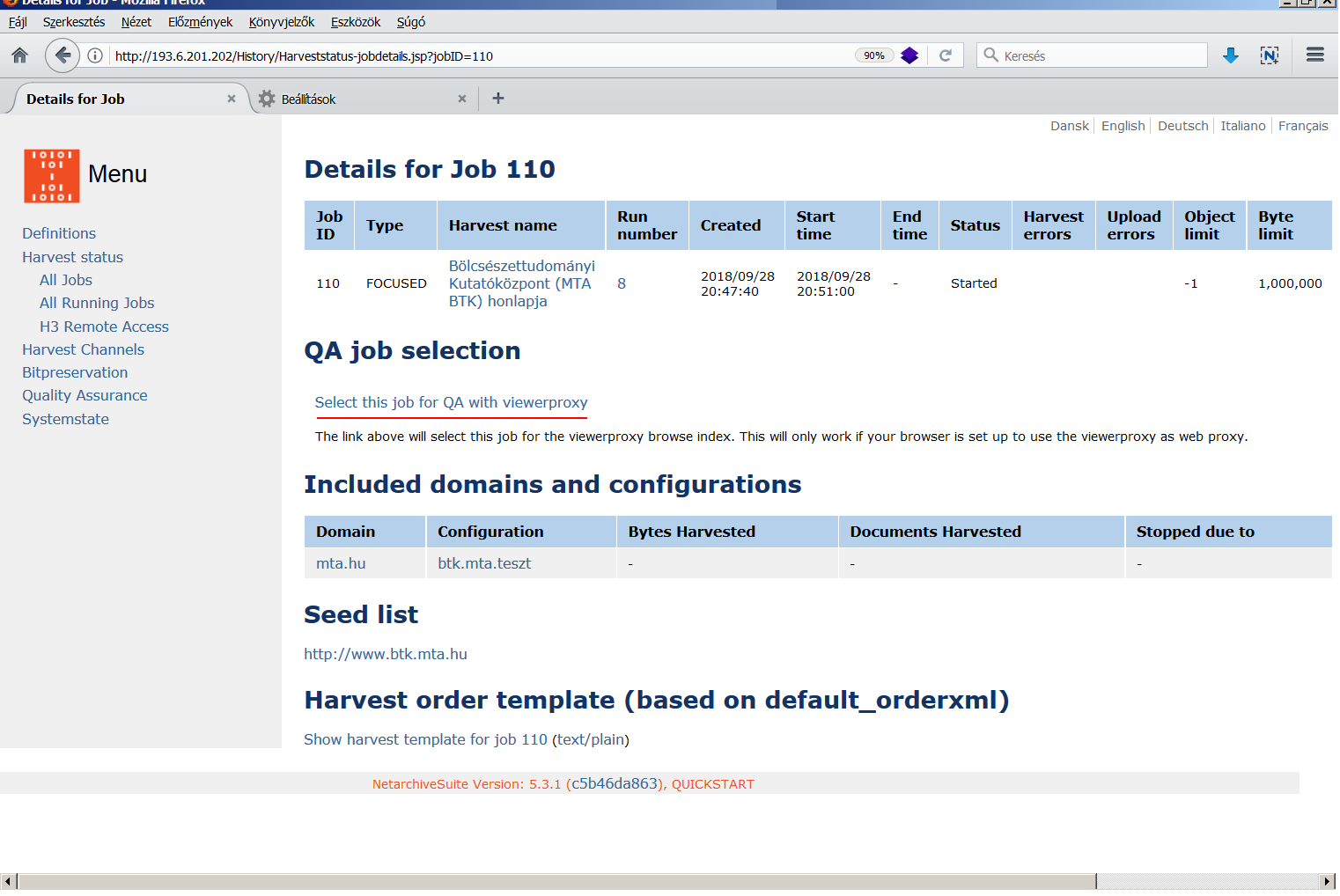
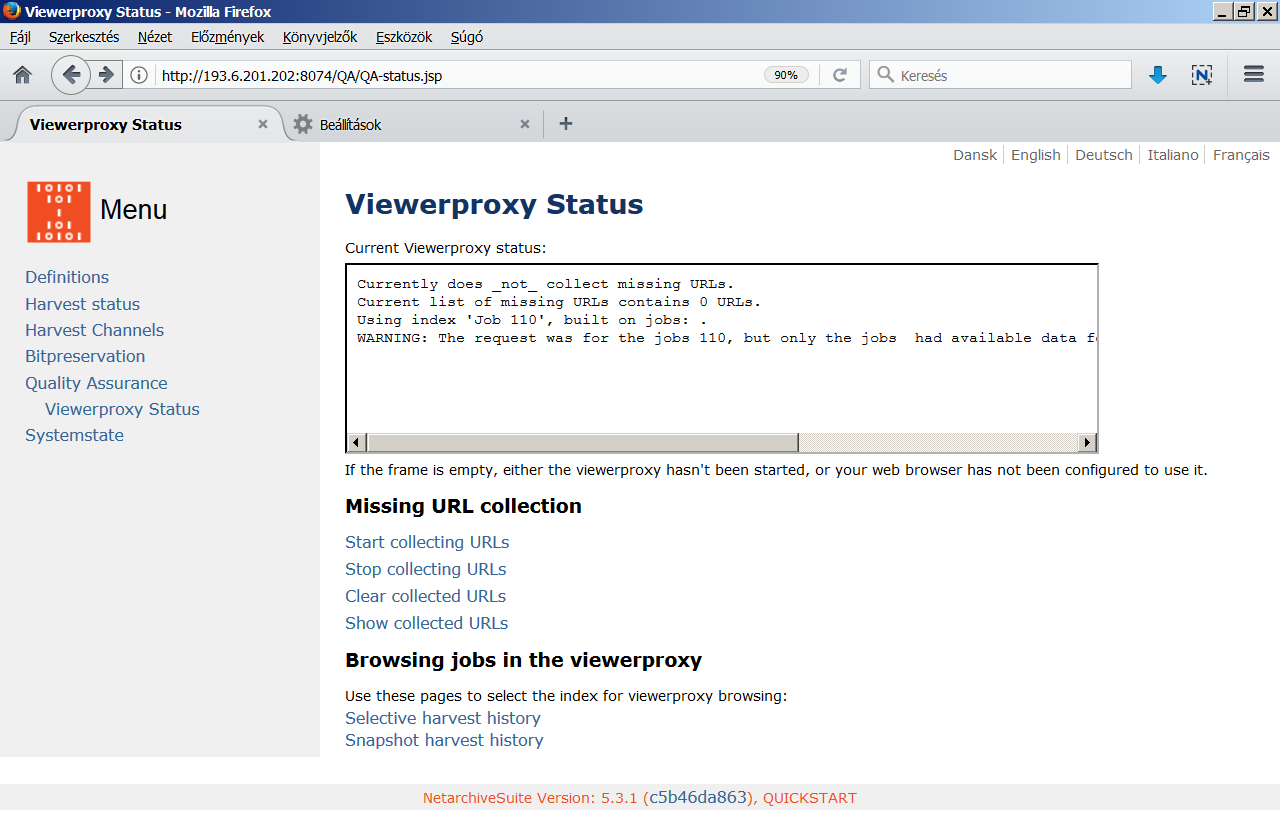
A NetarchiveSuite [wiki szócikk] is egy nyílt forráskódú keretrendszer a Heritrix vezérléséhez. <3.2.2_nas1.png> Fejlesztése 2005-ben indult két nagy dán könyvtár együttműködésében, melyhez később más nemzeti könyvtárak (pl. francia, osztrák, spanyol, svéd) is csatlakoztak. A WCT-től eltérően nem tartalmaz engedélykérést segítő funkciókat és kevésbé alkalmas metaadatolásra, mert bár az adatmezők száma bővíthető, de csupán domén-szintű leírásra van lehetőség. A Heritrix paraméterezésére az űrlapos felületen csak néhány opció van: a mentendő fájlok maximális száma, a letölthető maximális összméret, a hipertext ugrások száma a kezdőponttól, a robots.txt-ben [wiki szócikk][15] levő tiltások tiszteletben tartása, és a weboldalakon levő Javascriptek végrehajtása. Viszont feltölthetünk a rendszerbe tetszőleges számú, eltérő beállításokat tartalmazó konfigurációs fájlt, melyek közül bármelyiket hozzákapcsolhatjuk egy-egy doménhoz. Szintén hasznos funkció, hogy kizárhatunk az aratásból olyan URL címeket, amelyek végtelen ciklusba vezetnék a robotot [crawler trap][16]. A Selective Harvest űrlap alján találunk egy Event harvest funkciót, ahol akár egy több ezer URL címet tartalmazó seed-listát is feltölthetünk, így tömeges aratások is indíthatók. <3.2.2_nas2.png> Némileg hasonló célt szolgál a Snapshot Harvest menüpont is, ezzel ugyanis az összes, a rendszerben eddig definiált domén aratása egyszerre és azonnal elindítható. A mentések a Wayback proxy üzemmódjával nézhetők vissza, <3.2.2_nas3.png> és a Missing URL collection funkcióval kigyűjthetők azok a linkek az archív anyagból, amelyek mentése valamilyen ok miatt (pl. a paraméterként megadott határértékek elérése miatt) nem történt meg. <3.2.2_nas4.png> A kimaradt linkek közül a fontosak hozzáadhatók a seed-listához, hogy egy következő aratásba ezek is belekerüljenek. A NAS különlegessége az ArcRepository modul az ARC/WARC fájlok hosszú távú megőrzésére és az ezek sérülésmentességének ellenőrzésére használható Bitpreservation menüpont. A NAS-hoz ezenkívül még egy sor parancsmódban futtatható segédeszköz (Additional Tools) is tartozik speciális feladatokra. <3.2.2_nas.mp4>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ajánlott források: 1. NetarchiveSuite Documentation
3. A SolrWayback és a SolrMIA kereső
3.1. A SolrWayback szoftvercsomag
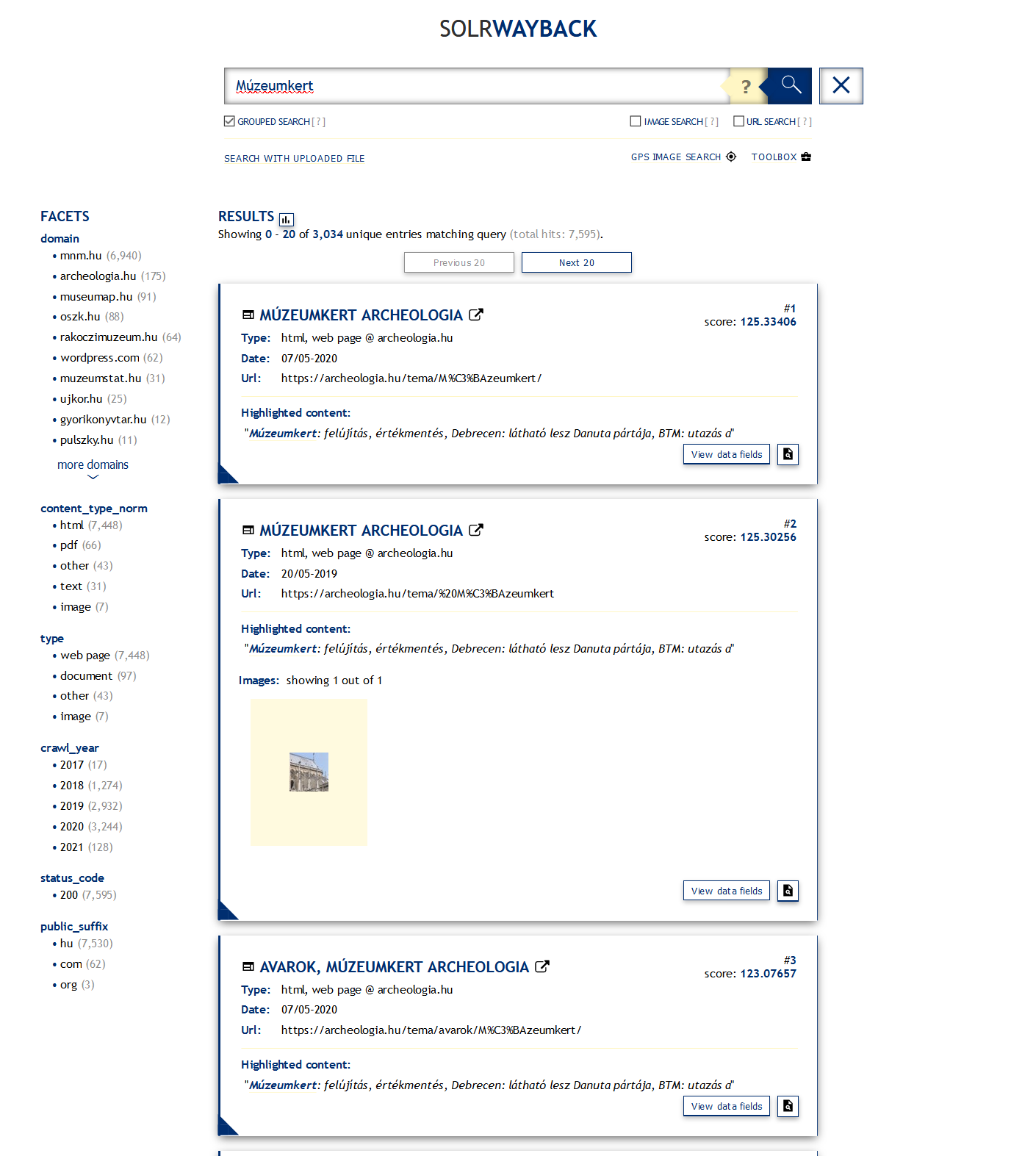
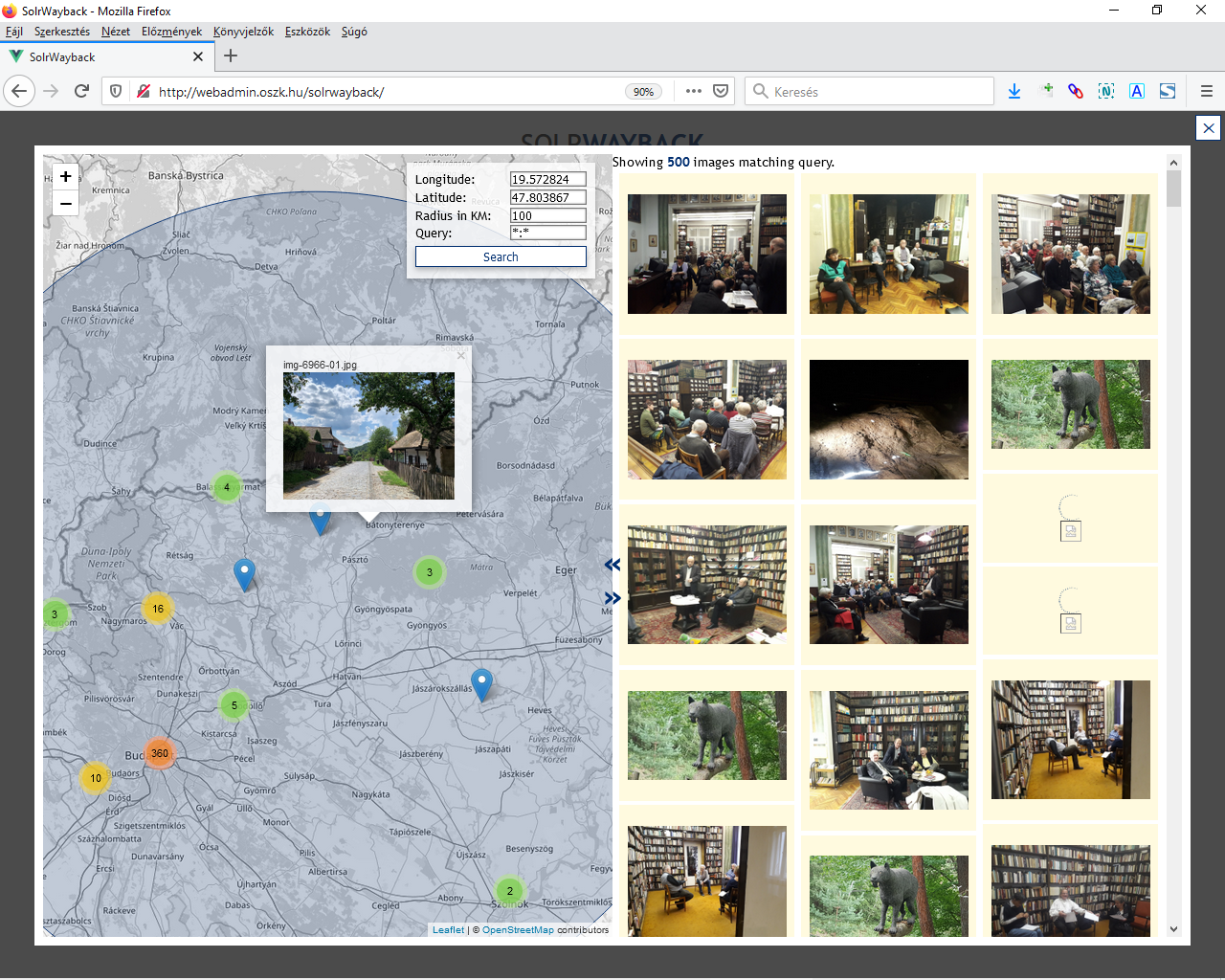
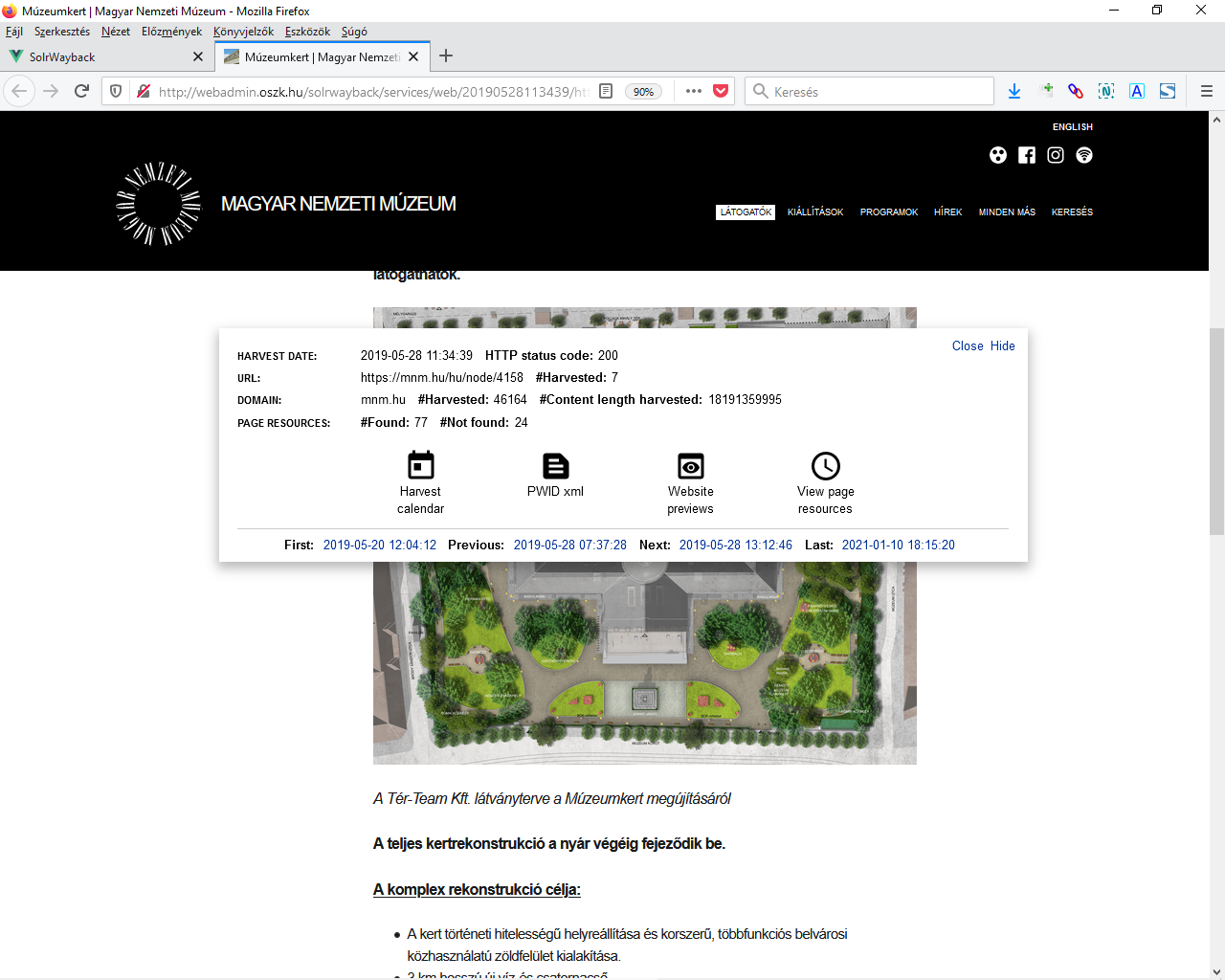
A SolrWayback [wiki szócikk] szoftvercsomagot is dánok fejlesztik, felhasználva hozzá a British Library webarchívumához készült WARC indexelőt és az általános célú Solr keresőt. [wiki szócikk] <3.3.1_solr.png> (Tehát ez nem a Wayback által használt CDX indexfájlokra épül.) A Waybackhez hasonlóan képes megjeleníteni az ARC/WARC fájlok tartalmát és a beépített proxy-nak köszönhetően kiküszöbölhető vele a live web leakage [wiki szócikk][17] probléma, vagyis hogy az élő webről jelenjenek meg a mentett oldalakba beágyazott tartalmak. Teljes szövegű- és képkereső is van benne, <3.3.1_swb1.png> <3.3.1_swb2.png> sőt egy, a felhasználó által feltöltött fájl előfordulását is meg tudja keresni az archívumban. A keresőmező alatti Toolbox menüponttal, valamint az egyes archív weblapokon kinyitható Toolbar panelen <3.3.1_swb3.png> pedig olyan funkciókat találunk, mint szófelhő generálás, az adott doménről kifelé mutató vagy arra kívülről hivatkozó linkekből rajzolt gráf, <3.3.1_swb4.png>, egy doménről letöltött tartalom időbeli változása, szavak előfordulási gyakoriságának alakulása, illetve egy adott oldal mentéseinek időbeli elosztása naptárszerű nézetben, a mentésekből generált bélyegképek, valamint a weboldalt alkotó elemek letöltési idejének eltérései. A találati listában a View data fields feliratra kattintva megnézhető a dokumentum összes technikai metaadata, a mellette levő kis ikonnal pedig a warc fájl fejléce. <3.3.1_swb.mp4>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ajánlott források: 1. About SolrWayback 2. SolrWayback kereső az OSZK demó webarchívumában
3.2. A SolrMIA kereső
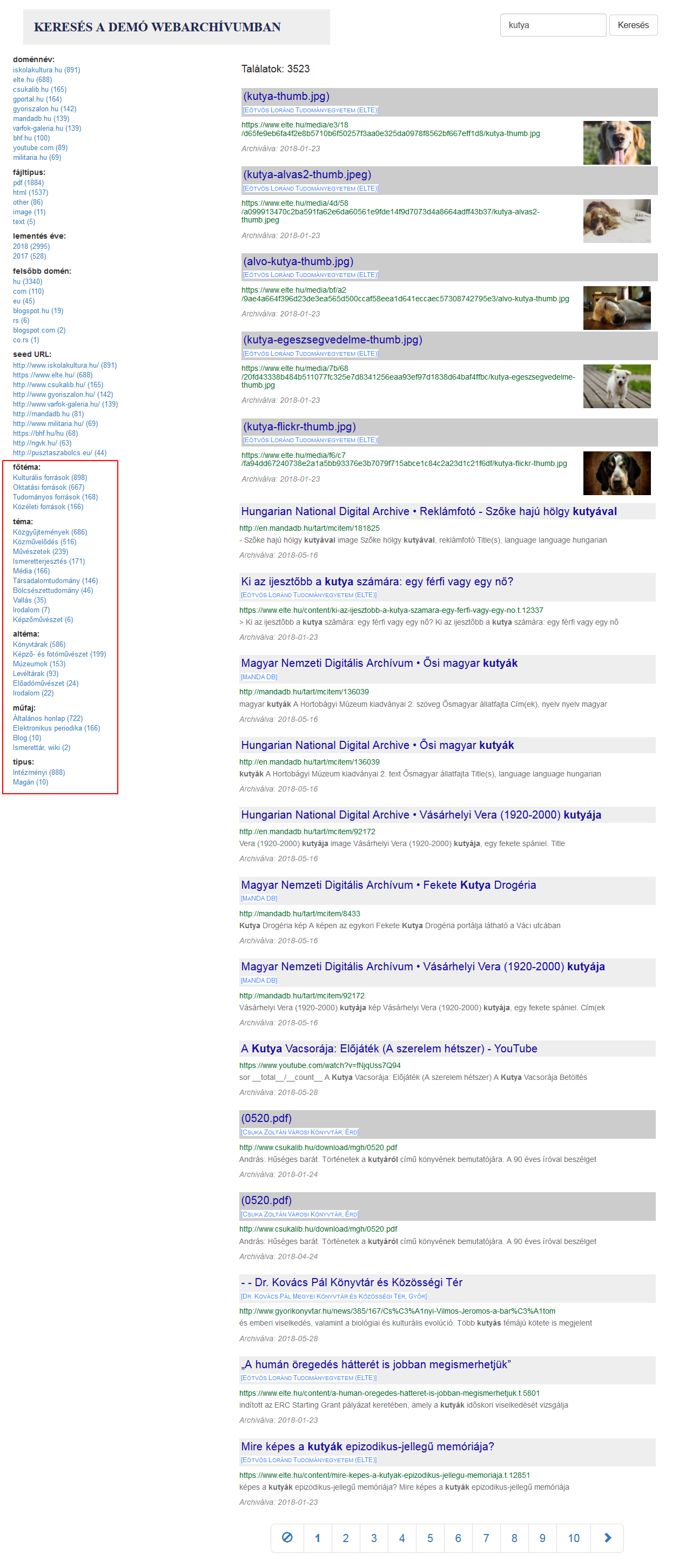
Az OSZK-ban a Magyar Internet Archívumot megalapozó projekt keretében 2018 elején elindult egy – szintén a Solr szerverre épülő, de az Open Wayback megjelenítőt használó – teljes szövegű kereső fejlesztése SolrMIA néven. Ez kihasználja a magyar nyelvhez készült szótövező algoritmust, vagyis a beírt szavak ragozott és képzett alakjait is megtalálja, valamint kizár az indexelésből egyes kötőszavakat, névmásokat, határozószókat és egyéb gyakori szavakat (stopwords), továbbá a felülete is magyar nyelvű. A találati lista szűkíthető doménnévre, fájltípusra, mentési évre, seed URL-re, valamint témakörre, altémakörre és műfajra is. <3.3.2_solrmia.png> Utóbbi adatok a webkönyvtárosok által gondozott metaadat nyilvántartásból származnak, akárcsak a webhely neve, ami minden találat alá kiíródik, segítve az eredeti forrás beazonosítását. Ugyancsak az „értelmesebb” találati listák generálását célozza az a megoldás, hogy ha egy weboldalnak vagy egyéb fájlnak nincs önálló címadata, akkor helyette a fájlnév jelenik meg, ami jó esetben hordoz valamiféle jelentést. A találatok alatt az eredeti szerverre mutató zöld linkre kattintva megnézhető az adott oldal aktuális állapota, amennyiben az még elérhető az élő weben. (A SolrMIA fejlesztése 2019-ben leállt, a benne megvalósított plusz funkciók a tervek szerint a SolrWayback jövőbeli verzióiba lesznek beépítve.)
{kind=link}
4. Minőségellenőrzés és metaadatolás
4.1. Mentett webhelyek minőségellenőrzése
A web az eddig feltalált legkomplexebb médium, ezért megőrzése során számos (vagy inkább számtalan) technikai probléma léphet fel. Ezek egy része a crawler beállításainak módosításával vagy a seed-lista bővítésével/szűkítésével, esetleg egy más típusú aratószoftver használatával orvosolható. Más esetekben az eredeti szolgáltatót, webmestert kell megkérni, hogy vagy a robots.txt módosításával, vagy a webhelyen alkalmazott megoldások (pl. Flash, Java, Javascript, Ajax elemek) megváltoztatásával alakítsa robotbaráttá [crawler-friendly] és archívumbaráttá [archive-friendly] a szolgáltatását. (Ha ez sem kivitelezhető, akkor pedig meg lehet állapodni vele, hogy valamilyen más módon – pl. RSS csatornán, OAI-PMH protokollon át, ResourceSync szinkronizálással, offline beadott csomagban – juttassa el a digitális tartalmait az archívumba.) Hogy mikor milyen megoldást érdemes választani, ahhoz szükség van a mentett anyag minőségének ellenőrzésére (quality review, quality assurance, QA), aminek mértékére és mélységére persze határt szab az ellenőrizendő weboldalak mennyisége és a rendelkezésre álló munkaerő. Egy nagyobb archívum esetében erre csak szúrópróbaszerűen van lehetőség, lehetőleg automatikus vagy félautomatikus megoldásokat is igénybe véve.
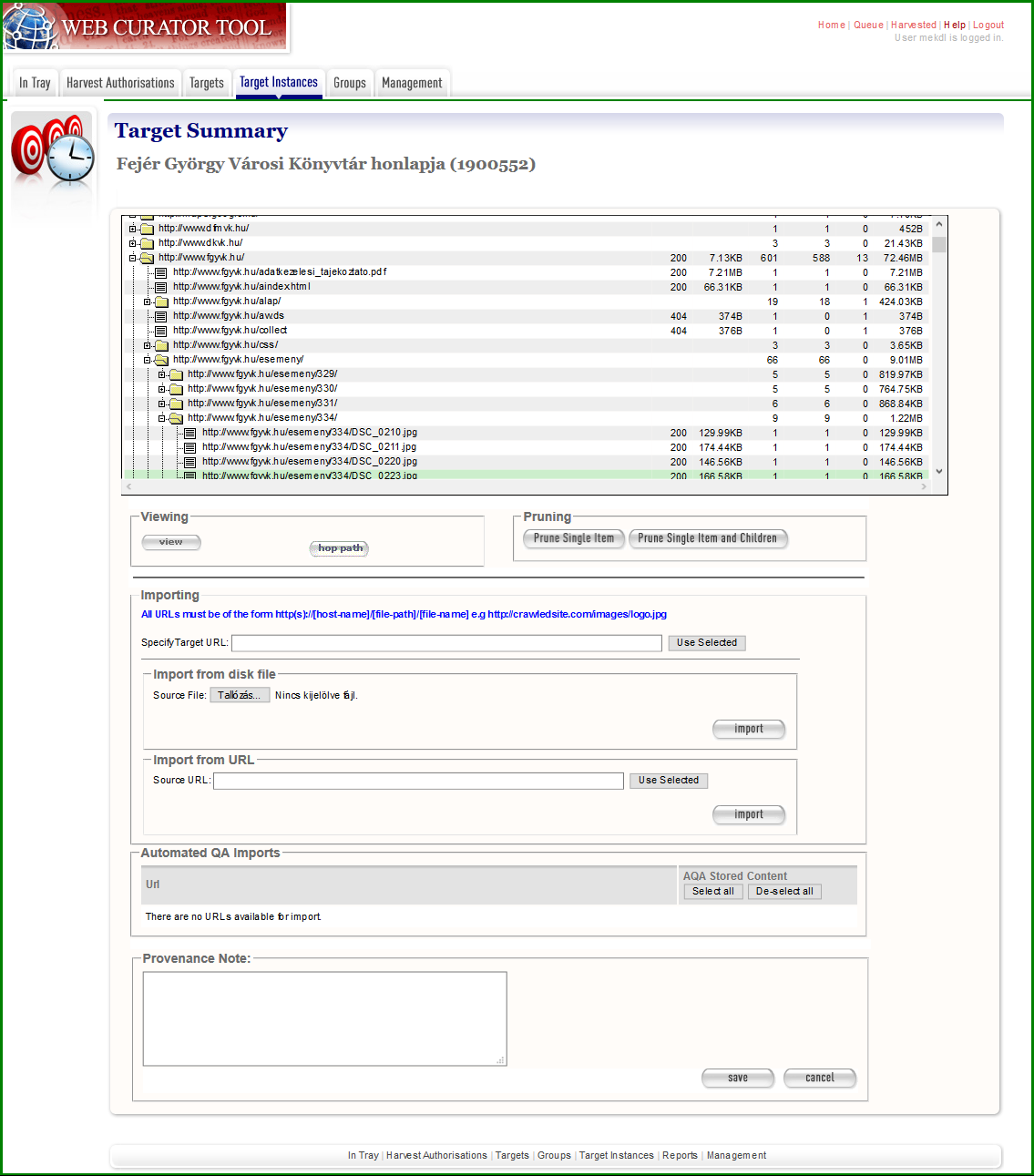
[Eszközök az ellenőrzéshez] A minőségellenőrzés már az aratás előtt elkezdődhet olyan eszközökkel, mint pl. a Wappalyzer [wiki szócikk], a Link Grabber, az Archive Ready [wiki szócikk], vagy a Spider Test Tool [wiki szócikk], amikkel előre felderíthető, hogy egy adott webhely milyen technológiákat használ, milyen más doménekre vagy aldoménekre linkel, mennyire archiválható, illetve bejárható-e robottal? De hasznos lehet az is, ha megnézzük az Internet Archive-ban az illető webhely legfrissebb mentését, ami alapján szintén képet alkothatunk annak – Heritrix-szel való – archiválhatóságáról. Ezt természetesen az archiválás után is megtehetjük, összehasonlítva azt a saját mentésünkkel, valamint az élő webhellyel, hogy vajon mi az, ami nem jelenik meg vagy nem működik a mi archív példányunkban? A Web Curator Tool a Target Instances menüpontnál az Edit gomb alatti Harvest Results fülön biztosít egy Review funkciót ezekre az összehasonlításokra. Ugyanitt találunk egy Harvest History Tool feliratot is, amire kattintva az adott webhely korábbi mentéseit vethetjük össze, és ha jelentős eltérést látunk a mentett anyag mennyiségében vagy a sikertelenül lekért URL címek számában, akkor vagy nagyon megváltozott az eredeti webhely, vagy valami hiba történt az aratás során. A Tree Tool eszközzel a mentett oldalakból kigyűjtött linkeket látjuk domének szerint rendezett hierarchikus fa nézetben, ahol kinyitogathatjuk és becsukogathatjuk az egyes ágakat, sőt le is vághatjuk a szükségteleneket (prune) vagy újabbakat adhatunk hozzájuk (import). Az így átszabott seed-lista a webhely következő aratásánál lesz figyelembe véve, s remélhetőleg pontosabb és/vagy kevesebb „szemetet” tartalmazó mentést eredményez. <3.4.1_wct.png>
{kind=link}
[Egyéb ellenőrzési módszerek] Nagyon hasznos hibafelderítő, de több szakértelmet igénylő módszer a Heritrix által létrehozott jelentés (report) és napló (log) fájlokban levő adatok és hibaüzenetek (pl. a szerver által visszaadott státuszkódok [wiki szócikk][18]) tanulmányozása. Ezeket a szövegfájlokat a WCT-ből és a NAS-ból is (és természetesen a Heritrix saját adminisztrációs felületéről is) meg tudjuk nézni.
Hogy egy élő vagy egy mentett weboldal milyen beágyazott médiaelemeket tartalmaz, milyen Javascript vagy egyéb kódok vannak benne, tartalmazza-e a külalakját definiáló utasításokat vagy külső stílusfájlból (CSS file) tölti be azokat, vannak-e a fejlécében a robotokra vonatkozó tiltások, használ-e sütiket (cookies) stb., azt a böngésző Eszközök menüjéből elérhető Oldal adatai és Oldal forrása (Ctrl/U), s az egyéb Webfejlesztő (F12) funkciók segítségével deríthetjük ki. Az egyes képeket és linkeket pedig a jobb egérgombbal rájuk kattintva vizsgálhatjuk meg tüzetesebben.
[Hibajelenségek 1.] Az egyik leggyakoribb hibajelenség, hogy vagy semmit sem sikerült letölteni, vagy bizonyos fontos fájlok hiányoznak a mentésből. Az előbbinek két fő oka lehet: vagy elérhetetlen volt az adott webhely (pl. szerverhiba, vagy végleges megszűnés miatt), vagy ki vannak róla tiltva a robotok. Ilyenkor érdemes egy böngészőben a honlap kezdő URL címe után a /robots.txt szöveget beírva ellenőrizni, hogy van-e robots.txt fájl az adott webhelyen és ha igen, akkor mi van benne? Továbbá azt is, hogy az aratószoftver beállításai között a robot-tiltások tiszteletben tartása be volt-e kapcsolva a mentéskor, illetve hogyha nincsen robots.txt az adott webhelyen, akkor egyáltalán elindul-e a crawler? (A Heritrix alapbeállítása szerint ilyenkor úgy viselkedik, mintha kitiltották volna.) Az is előfordulhat, hogy csak bizonyos típusú böngészőket szolgál ki az illető webszerver és ezért nem válaszolt a robotunk kéréseire. Ezt pl. a User Agent Switcher [wiki szócikk] Firefox kiegészítő telepítésével tesztelhetjük, amiben a Firefox saját azonosítója [user-agent][19] helyett beállíthatjuk a crawler konfigurációs állományában levő azonosítót és kipróbálhatjuk, hogy így meg tudjuk-e nézni az adott weboldalt? Ha nem, akkor a konfigurációs fájlban a user-agent átírásával kiadhatjuk a robotunkat egy aktuális Firefox vagy Chrome böngészőnek, és így már valószínűleg sikerülni fog az aratás. A legtöbb crawler beállításai közt amúgy arra is van lehetőség, hogy figyelmen kívül hagyja a robots.txt-t, de ez csak indokolt esetben, lehetőleg a tartalomszolgáltató tudtával, illetve erre feljogosított nemzeti webarchívumok esetében megengedett az internetes etikett szerint. Fontos az is, hogy kellően „udvarias” [polite] módban futtassuk az crawler-t, mert ha túl sok kérést intéz túl rövid idő alatt a webszerverhez, akkor az túlterheléses támadásnak érzékelheti és ezért tiltja ki.
[Hibajelenségek 2.] Ha csak bizonyos elemek (pl. a külalakot beállító CSS fájl, vagy egyes beágyazott képek, videók) hiányoznak, annak is több magyarázata lehet. Okozhatja ezt is a robots.txt (pl. bizonyos CMS [wiki szócikk][20] rendszerekben a .css kiterjesztésű fájlok alkönyvtára eleve ki van tiltva, hiszen a Google és más keresőgépek számára ezek érdektelenek); vagy pedig az aratásnál túl szigorúra állítottuk a paramétereket (pl. a robot nem ment le arra a mélységre; vagy nem követte a külső szerverre mutató linkeket, illetve nem szedte le az onnan beágyazott tartalmat; vagy elérte a maximális objektumszámot, mérethatárt, futási időt; vagy csak bizonyos fájlformátumok ki voltak zárva). Ez esetben a beállítások módosításával, esetleg további seed URL-ek hozzáadásával orvosolhatjuk a problémát. A képek hiányának lehet az is az oka, hogy az eredeti webszerveren reszponzív felület van és az srcset attribútum alapján a szerver olyan méretben küldi el a képeket, amelyek illeszkednek a kliens által használt ablakmérethez/képernyő felbontáshoz. Ha az archiváló szoftver nincs felkészítve erre a megoldásra, akkor csak egy adott méretben kerülnek lementésre a képek és visszanézéskor egy eltérő méretű képernyőn nem fognak megjelenni.
[Hibajelenségek 3.] Főleg a közösségi médiában (pl. Facebook, Twitter, blogok) és a hírportálokon gyakori megoldás, hogy az oldal felső része alatti ill. régebbi tartalmak csak olyankor töltődnek le a szerverről, ha a felhasználó lejjebb görget, amit a Heritix-szerű robotok nem tudnak leutánozni, ezért csak az oldal tetején levő szövegeket, képeket mentik le. Ilyenkor érdemes egy olyan archiváló eszközt választani, amiben van autoscroll funkció. Sokszor pedig azért hiányoznak egyes elemek az archivált webanyagból, mert az azokra hivatkozó linkeket olyan programok állítják elő vagy olyan fájlokban találhatók, amiket a robotunk nem értelmez. Ha lehet, akkor célszerű bekapcsolni, hogy a Javascript, Java, Flash, CSS kódokban, sőt esetleg a videó és PDF fájlokban levő linkeket is próbálja meg felismerni és követni a robot.
[Megjelenítési problémák] Előfordulhat az is, hogy a hiányzó fájlt valójában letöltötte a robot, csak az valamiért nem látszik a megjelenítő felületen (pl. a Wayback-ben), mert esetleg a linket nem sikerült átírni lokálisra (pl. egy ékezetes fájlnév miatt); vagy az eredeti szerver olyan cookie-t vagy session azonosítót használ, ami az archívumban már lejárt; vagy mert bizonyos tartalmak (pl. videók) lejátszása az eredeti szerveren futó programokhoz van kötve. Ha megnézzük az illető fájlhoz tartozó URL címet az élő weben és rákeresünk ugyanerre az archívumban, akkor ellenőrizni tudjuk, hogy le lett-e mentve. <3.4.1_archive_errors.pptx>
Természetesen semmilyen olyan interaktív funkció nem fog működni az aratással archivált oldalakon, amelyekhez szerveroldali programok vagy adatállományok tartoztak eredetileg (pl. az adott webhelyen belüli vagy az ottani adatbázisokban való keresés), mert ezeket vagy le sem tölti a robot, vagy nem tudja őket futtatni a megjelenítő.
[Túl sok letöltött fájl] Egy másfajta gond, amikor túl sok tartalmat tölt le a robot rengeteg tárhelyet elfogyasztva és esetleg végtelen ciklusban keringve. Ennek lehet az az oka, hogy rosszul mértük fel a webhely méretét és valójában jóval nagyobb, mint aminek látszik; vagy túl lazára állítottuk a paramétereket és a robot túl mélyre ment ill. elindult a külső szerverekre és azokat is elkezdte letölteni; vagy pedig belefutott egy már említett csapdába [crawler trap][21], például egy öröknaptárba. Az ilyen típusú problémákat a naplófájlok nézegetésével lehet felderíteni és a robot viselkedését befolyásoló konfigurációs beállítások és seed-listák módosítgatásával lehet megpróbálni megoldani.
Ajánlott források: 1. WCT User Manual („Target Instance Quality Review” fejezet), 2. Improving the quality of web harvests using Web Curator Tool 3. Útmutató a szelektíven archivált egyedi webhelyek minőségellenőrzéséhez
4.2. Webarchívumok metaadatolása
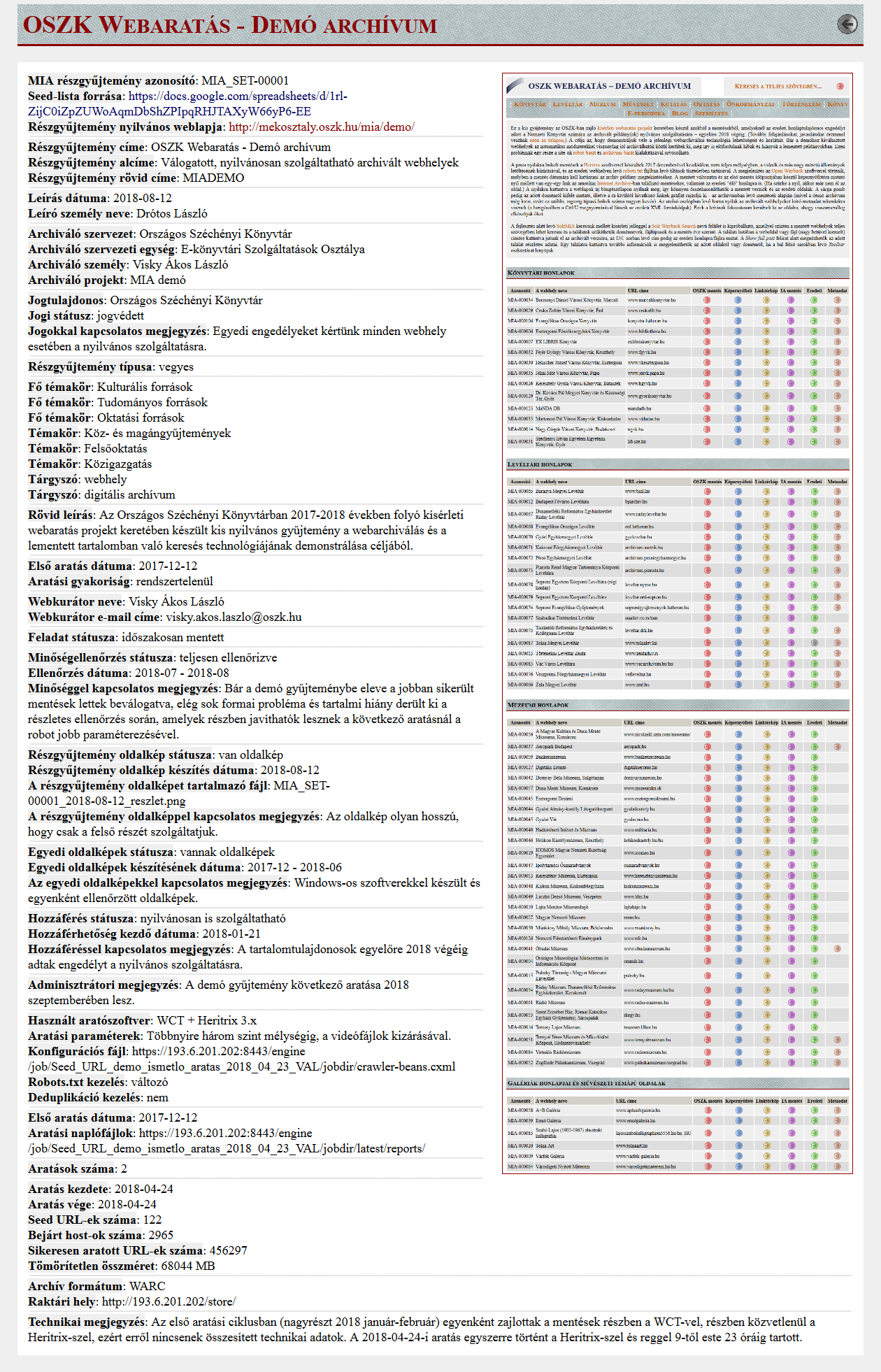
Az internetes tartalmak műfaji és formai változatossága miatt nem egyszerű ezek archivált változatainak könyvtári szempontú leírása. Míg mondjuk egy elektronikus folyóirat esetében elég egyértelmű, hogy milyen adatokat érdemes rögzíteni róla és milyen MARC mezőkben, addig például egy online fórum vagy egy Twitter csatorna sokkal kevésbé hasonlít a könyvtárakban előforduló hagyományos dokumentumtípusokra, ezek nyilvántartására a levéltári megközelítés alkalmasabb lehet. Eldöntendő kérdés az is, hogy milyen részletességi szintig dolgozzuk fel az archivált anyagot? Készüljenek-e önálló adatrekordok egyedi (pl. PDF vagy videó) fájlokról? Az ausztrál PANDORA archívumban az együttműködő könyvtárak munkatársai leírnak fontos egyedi dokumentumokat is, de ez máshol nem jellemző. A következő szint a webhelyrész, ami annyira összefüggő egységnek tekinthető a teljes webhelyen belül, hogy érdemes külön (is) leírni és így visszakereshetővé tenni (pl. egy virtuális kiállítás egy könyvtár honlapján, vagy egy e-folyóirat egy egyetemi intézet webszerverén). A szelektíven gyűjtött webhelyekből álló archívumoknál a webhelyek szintjét mindenképpen metaadatolni szokták. Akár már a válogatás során készül mindegyikről egy adatrekord, amit a mentés után még kiegészítenek, pontosítanak. A teljes országdoménre (pl. .uk) vagy nagyobb aldoménre (pl. .gov.uk) kiterjedő aratások anyagánál olyan nagy munka lenne minden webhelyet önállóan feldolgozni, hogy ettől eltekintenek, vagy esetleg csak aldomén ill. al-aldomén szintű leírást készítenek a fontosabbakról, vagy csak a teljes anyagot látják el néhány adattal. Az esemény- vagy téma-alapú aratásokból keletkező halmazok, részgyűjtemények szintén elláthatók metaadatokkal és szoktak is ilyen szintű leírásokat készíteni. Végül magáról a teljes webarchívumról is adhatunk meg információkat (pl. gyűjtőkör, összetétel, méret, használati adatok), van is egy erre vonatkozó 2013-as ISO ajánlás ISO/TR 14873 azonosító alatt.
[Adatcsoportok] A digitális objektumokhoz rendelhető metaadatok négy csoportba sorolhatók: leíró, szerkezeti, technikai és adminisztrációs. Ezek mindegyikére szükség lehet a webarchívumban található tartalmak esetében is. Az amerikai könyvtári szövetség, az OCLC által 2015-ben létrehozott munkacsoport, a Web Archiving Metadata Working Group az igények és a rendelkezésre álló szoftverek felmérése után 2018-ban kidolgozott egy javaslatot elsősorban a leíró adatokra a Dublin Core metaadat sémára alapozva. Ebben az olyan, értelemszerű bibliográfiai adatok, mint a cím, létrehozó, közreműködő, téma, típus, nyelv, jogi státusz stb. mellett bevezettek olyan mezőket, mint a leíráshoz használt forrás és a begyűjtő szervezet. (Előbbire azért lehet szükség, mert egy webhely esetében nem mindig evidens, hogy például a főcímet honnan vettük. Utóbbi pedig olyankor hasznos, ha egy webarchívumot közösen épít több intézmény vagy szervezeti egység.) Egyes adatok automatikusan is kigyűjthetők a weboldalak HTML fejlécéből (pl. a főcím a title sorból, a téma a keywords metaadat mezőből, a nyelv pedig a lang paraméterből), de nem árt, ha ezekre utána ránéz valaki, mert sok esetben hibásan vagy egyáltalán nincsenek megadva ezek az információk a honlapok forráskódjában. Szerkezeti típusú metaadat lehet például egy elektronikus periodika évfolyamainak, számainak, cikkeinek és esetleg a cikkekhez tartozó ábráknak, mellékleteknek, kommenteknek stb. a hierarchiája; vagy egy webhely belső linktérképe. A technikai adatok között célszerű rögzíteni az aratáskor használt paramétereket, a mentett fájlok formátumait, a webszerver által küldött esetleges hibakódokat, az aratásból kizárandó URL-eket stb. Ezek a metaadatok részben automatikusan létrejönnek, részben szintén automatizáltan kigyűjthetők, illetve hozzárendelhetők akár minden egyes fájlhoz az archívumban. [Metadata Extraction Tool] Például tudományos hivatkozásokhoz nagyon hasznos tud lenni, ha nemcsak az egyes weboldalakhoz, hanem azokon belül minden objektumhoz (pl. ábrához) stabil azonosítót generál a rendszer. Az adminisztrációs metaadatok a munkafolyamatok nyilvántartását segítik. Ide tartozhat többek közt az adott webhely archiválásáért felelős munkatárs és esetleg a javaslattevő neve, az eredeti tartalomgazda vagy egyéb illetékes kapcsolattartó elérhetősége, az engedélyezéssel, a minőségellenőrzéssel és a hozzáférhetőséggel kapcsolatos információk, a mentések gyakorisága és sürgőssége (pl. ha rövidesen megszűnik az adott honlap), továbbá annak a jelzése is, hogy az adott webhely olyan fontos és a mentése olyan minőségben sikerült, hogy érdemes felvenni az adatait a könyvtár katalógusába és esetleg a nemzeti bibliográfiába is. <3.4.2_metaadat1.png> <3.4.2_metaadat2.png> <3.4.2_metaadat_set1.png> <3.4.2_metaadat_set2.png>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
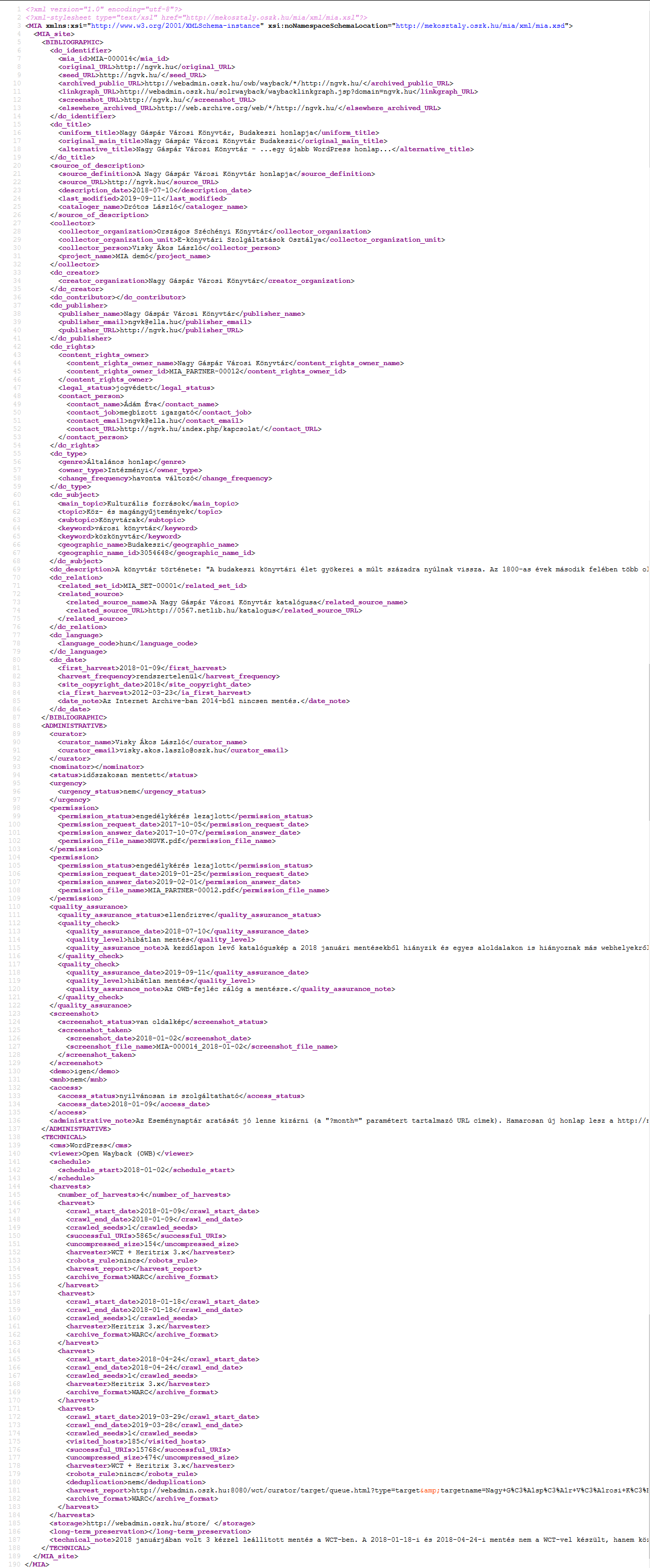
[Adatsémák] Összességében akár száznál is többféle adatot lehetne felvenni egy archivált webhely esetében, de természetesen, hogy ezek közül melyeket érdemes ténylegesen rögzíteni valamilyen adatbázisban, az a webarchívum méretétől, céljától, az automatizálhatóság fokától és a rendelkezésre álló munkaerőtől függ; mint ahogy az is, hogy milyen adatsémát érdemes választani. A nemzetközi gyakorlatban a Dublin Core [wiki szócikk], a MODS [wiki szócikk], a METS [wiki szócikk], a MARC stb. használata egyaránt előfordul, és több helyen a PREMIS [wiki szócikk] adatmodell által definiált öt elemtípust (intellectual, object, event, agent, rights) vették figyelembe a webarchívum metaadat-struktúrájának kialakításakor. Az OSZK projektjénél jelenleg használt, XML-alapú adatszerkezet a http://mekosztaly.oszk.hu/mia/xml/ címen található. Ennek RDA (Resource Description and Access) alapokon való továbbfejlesztése 2019-ben kezdődött el. (A cseh webarchívumnál is RDA elvek szerint történik a katalogizálást.)
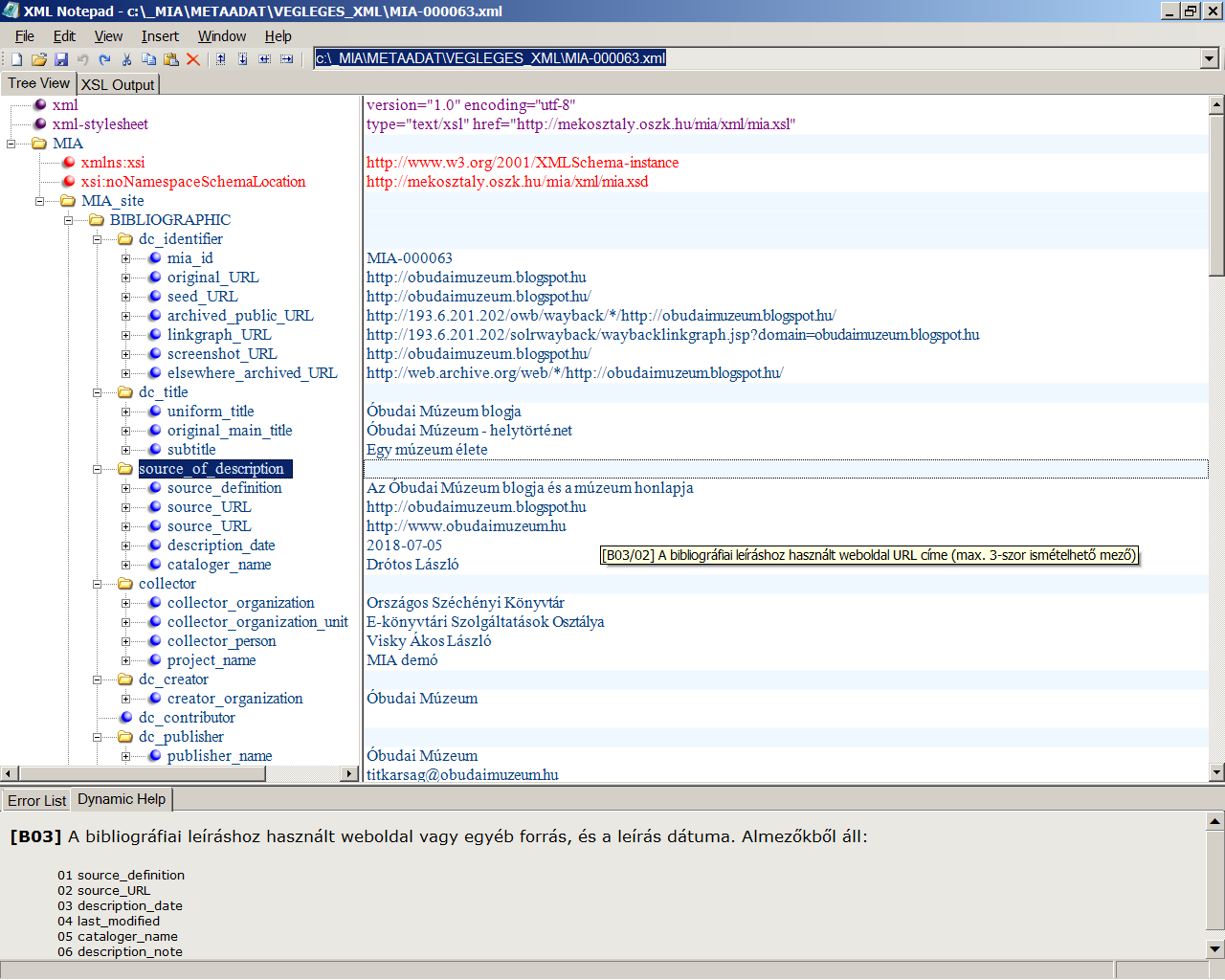
[Adatbázisok] Az adatok rögzítésére és visszakeresésre használt szoftver esetében is sokféle megoldással találkozunk: van, ahol saját programot írtak erre a feladatra, vagy a WCT ill. a NAS beépített adatkezelőjét használják, máshol egy olyan általános célú digitális könyvtári rendszerrel tartják nyilván az archivált webanyagokat, mint a Fedora vagy a DSpace, de arra is találunk példákat, hogy a webarchívumot összekapcsolták az integrált könyvtári rendszerrel és annak a katalogizáló modulját használják a leíró adatokhoz, az adminisztrációs és technikai metaadatokat (beleértve a hosszú távú megőrzéshez szükséges információkat) pedig a digitális raktári rendszerrel (pl. Rosetta) kezelik. De akár egy egyszerű XML szerkesztővel <3.4.2_xmlnotepad.png> is tudunk egészen komplex leírásokat készíteni. <3.4.2_xmlnotepad.mp4>
{kind=link}
Ajánlott források: 1. OCLC Web Archiving Metadata Working Group, 2. Jackie Dooley - Kate Bowers: Descriptive Metadata for Web Archiving, 3. Metadata for Web Archives, 4. ISO/TR 14873:2013 Statistics and quality issues for web archiving, 5. MIA metaadat ajánlás, 6. Metaadatolási útmutató egyedi webhelyekhez, 7. Metaadatolási útmutató részgyűjteményekhez
Összefoglalás:
Egy saját szerveren működő, intézményi vagy nemzeti szintű webarchívumot ingyenes szoftverekből is össze lehet rakni, melyek a szabványosodó fájlformátumoknak és adatcsere protokolloknak köszönhetően tudnak együttműködni. Szükség van legalább egy aratószoftverre és egy megjelenítő eszközre, egy munkafolyamat- és egy metaadat-nyilvántartó rendszerre, valamint teljes szövegű és metaadat keresőkre, továbbá néhány egyéb modulra is (pl. képernyőfotók készítéséhez, statisztikák generálásához, a WARC fájlok raktározásához, a hozzáférés szabályozásához). Fontos a mentések minőségellenőrzése, ezért jó, ha a rendszerben erre a feladatra is vannak beépített funkciók és az archívumot gondozó szakemberek pedig fel vannak készítve a tipikus problémák okainak felismerésére és kezelésére. Ahhoz, hogy a webarchívum több legyen, mint egy rendezetlen fájlhalmaz és magasabb szintű szolgáltatásokat is rá lehessen építeni, szükség van a letöltött anyag valamilyen szinten történő és valamilyen részletességű metaadatolására. A leíró, a szerkezeti, a technikai és az adminisztrációs jellegű metaadatok részben automatikus módszerekkel is előállíthatók, de lehetőség szerint ezeket emberi intelligenciával is érdemes átnézni és kiegészíteni.
Önellenőrző kérdések:
Mi a közös komponens a WAIL, a WCT és a NAS rendszerekben?
Milyen fajta hibajelenségek fordulnak elő az archivált webhelyeknél?
Lehet-e képekre keresni az Open Wayback-ben? És a SolrWayback-ben?
A metaadatok melyik csoportjába sorolható az az információ, hogy egy webhely a deduplikációs funkció bekapcsolásával lett-e ismételten elmentve?
Megoldandó feladatok:
-
A VirtualBox-ban elindítható WCT-vel mentse le 3 szint mélységben a https://mek.oszk.hu/kiallitas/lazar/ címen található Lázár Ervin virtuális kiállítást (kb. 25 perc). Majd a WARC fájl leindexelése után (kb. 3 perc) a Harvest Results menüpont alatt a Review funkcióval ellenőrizze az OWB-ben, hogy milyen hibák vannak a mentésben, és hogy működik-e a Galériák menüpont alatti Flash-képnézegető? Ugyanitt a Tree View funkcióval ellenőrizze, hogy vajon le lettek-e egyáltalán mentve a https://mek.oszk.hu/kiallitas/lazar/html/galeriak/ alatti képfájlok? Hogyan lehetne ezeket is letölteni?
-
A http://archiveready.com szolgáltatás segítségével ellenőrizze a munkahelye honlapját, valamint a http://www.oszk.hu oldalt is, hogy hány százalékban archívum-barátok? A Summary-n kívül nézze meg a többi fülön levő információkat is! A Sitemaps lapon ellenőrizze, hogy van-e az adott webhelyen robots.txt fájl, és ha igen, akkor mely alkönyvtárakból tiltja ki a robotokat? A Media fül alatt pedig a weblapba ágyazott képek technikai metaadatai láthatók a JHOVE nevű eszközzel kigyűjtve. Keressen rá a MIA Wikiben a JHOVE-t ismertető szócikkre!
-
Keressen jó és rossz mentéseket a https://webarchivum.oszk.hu/demo-kezdolap/ címen levő demó webarchívumban. Hasonlítsa össze az OSZK-ban készült mentést az Internet Archive-ban levővel és az élő honlappal. Próbálja megállapítani, hogy mi okozhatja az eltéréseket?
-
A http://webadmin.oszk.hu/solrwayback/ keresővel találjon egy olyan weboldalt a demó archívumban, amely a Fugger család könyvtárából származó ex libriseket mutatja be. A találati listában előbb kattintson a View data fields feliratra és nézze meg az oldal technikai metaadatait, majd kattintson magára a találatra és a Toolbar panelen levő óra ikonnal ellenőrizze, hogy az oldalon levő képek milyen időkülönbséggel lettek elmentve, a naptár ikonnal pedig azt, hogy milyen időközönként készültek mentések erről az oldalról? Másolja vágólapra a megnézett weboldal eredeti doménnevét, majd a a találati listára visszatérve a keresőmező alatt levő TOOLBOX funkcióval generáljon egy linkgráfot erről a doménről. Próbálja ki, hogy hogyan változik a gráf, ha megnöveli vagy lecsökkenti a csomópontok (node-ok) számát, illetve ha az adott doménre mutató (Ingoing) linkeket ábrázolja.
JEGYZETEK
1 A weboldalakban levő linkeket követő szoftver.
2 Annak a weboldalnak az URL címe, ahonnan elindul a crawler.
3 A crawlert irányító programmodul a webaratás során.
4 Többszörösen lementett azonos fájlok eltávolítása.
5 Szabványos formátum a webről begyűjtött fájlok és technikai metaadatok tárolására.
6 A WARC formátum régebbi, egyszerűbb változata a webről begyűjtött fájlok és technikai metaadatok tárolására.
7 Parancsokkal vezérelhető, grafikus felhasználói felület nélküli webböngésző modul.
8 Programkódokkal előállított, általában a lekérés pillanatában generált, interaktív megoldásokat használó weboldal, illetve webhely (Rich Internet Application).
9 A WARC fájlokban tárolt digitális objektumok egyes technikai adatait tartalmazó szövegfájl.
10 A webarchívumban való böngészés során fellépő jelenség, amikor nem egy időben lementett tartalmak jelennek meg egymás mellett vagy a linkeket követve egymás után.
11 A webarchívumban való böngészés során fellépő jelenség, amikor az élő webről jelennek meg beágyazott tartalmak, vagy egyes linkek az archívumból kimutatnak az élő webre.
12 A webnek egy archiválásra kiválasztott része (pl. egy honlap vagy egyéb webhely).
13 Az aratások ütemezésének optimalizálása a technikai erőforrások jobb kihasználása érdekében.
14 Egy webhely egy adott időpontban készült mentése.
15 A robotok viselkedésének szabályozására használható szövegfájl egy webszerveren.
16 Weboldalak olyan sorozata, amely szándékosan vagy akaratlanul végtelen ciklusba vezeti a crawlereket.
17 A webarchívumban való böngészés során fellépő jelenség, amikor az élő webről jelennek meg beágyazott tartalmak, vagy egyes linkek az archívumból kimutatnak az élő webre.
18 A webszerver által a webböngésző kliensnek visszaadott kódszám, amely a klienstől kapott kérés teljesítésének sikerességét vagy hiba esetén annak okát jelzi.
19 A felhasználó nevében/helyett valamilyen feladatot ellátó szoftverek összefoglaló neve.
20 Olyan szoftverek gyűjtőneve, melyekkel egyszerűen lehet digitális/webes tartalmakat létrehozni, összeállítani és szolgáltatni (content management system).
21 Weboldalak olyan sorozata, amely szándékosan vagy akaratlanul végtelen ciklusba vezeti a crawlereket.


