
4. modul: Hasznosítás és fenntarthatóság
Bevezető gondolatok
Egy webes és/vagy egyéb internetes tartalmat gyűjtő archívum fenntarthatósága kulcskérdés: csak akkor van értelme belekezdeni, ha várhatóan évtizedekig működő- és fejlődőképes tud maradni, mert az idővel egyre nő az értéke a benne tárolt tartalomnak. A kockázatok közt a legnagyobb a technikai: lépést tudunk-e tartani a gyorsan változó digitális technológiával? elfogadható arányban, minőségben és gyakorisággal tudjuk-e lementeni a gyűjtőkörbe tartozó anyagot? sikerül-e kellő ütemben bővíteni a tárhelyet és azon hosszú távon is hibamentes és megtekinthető állapotban tartani a fájlokat? Ezen kihívások egy része alapvetően csak pénzkérdés, pénzt pedig akkor fordít egy intézmény, annak használói köre ill. fenntartója és/vagy szponzora egy szolgáltatásra, ha annak hasznosságáról meg van győződve. Ezért már az üzemszerű archiválás megkezdése előtt végig kell gondolni, hogy milyen (ingyenes vagy fizetős) szolgáltatások építhetők rá az archívumra és folyamatos ismeretterjesztéssel kell gondoskodni arról, hogy a potenciális felhasználók és támogatók tudjanak ezekről a lehetőségekről.
Mivel a digitálisan születő dokumentumok és egyéb online tartalmak száma meredeken nő, a másik nagy kockázat, hogy szakképzett munkaerővel lehet-e majd bírni a válogatási, az engedélyeztetési, a minőségellenőrzési, a metaadatolási és a rendszerfejlesztési feladatokat? Erre a válasz részben az automatizálható feladatok arányának növelése; részben formális és informális együttműködések kialakítása más közgyűjteményekkel, szervezetekkel, internetes cégekkel az élőmunkát igénylő feladatok megosztása céljából; részben pedig az „internet népének”: a tartalomelőállítóknak és -szolgáltatóknak, valamint az egyszerű felhasználóknak a bevonása pl. a gyűjtésbe, az ellenőrzésbe és a tárgyszavazásba. Az is fontos, hogy maguk a webarchívumok is együttműködjenek, például úgy, hogy közös formátumokat, metaadat sémákat, adatcsere és (esetleg) tartalomcsere protokollokat használnak; biztosítják a felhasználóik számára a különböző archívumokban való egyidejű kereshetőséget stb. Mivel minden webarchívum csak bizonyos időközönként készít mentéseket egy adott webhelyről, ezért nemcsak azt kellene koordinálni, hogy lehetőleg minden nyilvános oldalt mentsen legalább egy archívum, hanem azt is, hogy amelyiket több helyen is mentenek, azt hol milyen ütemezéssel érdemes aratni, hogy minél több állapota megmaradjon.
Célok, megszerezhető kompetenciák:
A modul célja, hogy a tanuló megismerje a webarchívumokra építhető szolgáltatásokat, valamint a lehetséges együttműködési formákat a webarchiválással foglalkozó intézmények között. A tananyag segítséget nyújt a nagyobb eséllyel fenntartható projektek és rendszerek kialakításához.
Szükséges eszközök, források:
Asztali számítógép vagy laptop internet kapcsolattal és webböngészővel.
Feldolgozási idő:
3×45 perc
Témakörök:
Irodalmak:
-
Drótos László - Kokas Károly: Webarchiválás és a történeti kutatások
In: Digitális Bölcsészet, 2018. (1. évf.), 1. sz.
http://ojs.elte.hu/index.php/digitalisbolcseszet/article/view/129 -
Németh Márton: A webarchiválásról történeti megközelítésben
In: Könyv, könyvtár, könyvtáros, 2018. (27. évf.), 2. sz.
http://ki2.oszk.hu/3k/2018/06/a-webarchivalasrol-torteneti-megkozelitesben/ - Németh Márton: Webarchívum mint a tudományos kutatások tárgya
In: Tudományos és Műszaki Tájékoztatás, 2020. (67. évf.) 12. sz.
https://tmt.omikk.bme.hu/tmt/article/view/12804 - Németh Márton: A mikroadatok felhasználása webarchiválási környezetben
Networkshop 2020 konferencia, Pécs
http://ocs.mtak.hu/index.php/nws/2020/paper/view/50 - Visky Ákos László: Gyorsmérleg az OSZK Webarchívum és a KDS-K
pályázat nyerteseinek együttműködéséről
In: Könyv, könyvtár, könyvtáros, 2020. (29. évf.), 7-8. sz.
http://ki2.oszk.hu/3k/2020/10/gyorsmerleg-az-oszk-webarchivum-es-a-kds-k-palyazat-nyerteseinek-egyuttmukodeserol1/
1. Hasznosítási lehetőségek
A hosszú távra tervezett archívumok esetében a fenntarthatóság egyik fontos feltétele, hogy a beléjük fektetett pénz és munka valamilyen módon megtérüljön a rájuk épülő szolgáltatásokon keresztül.
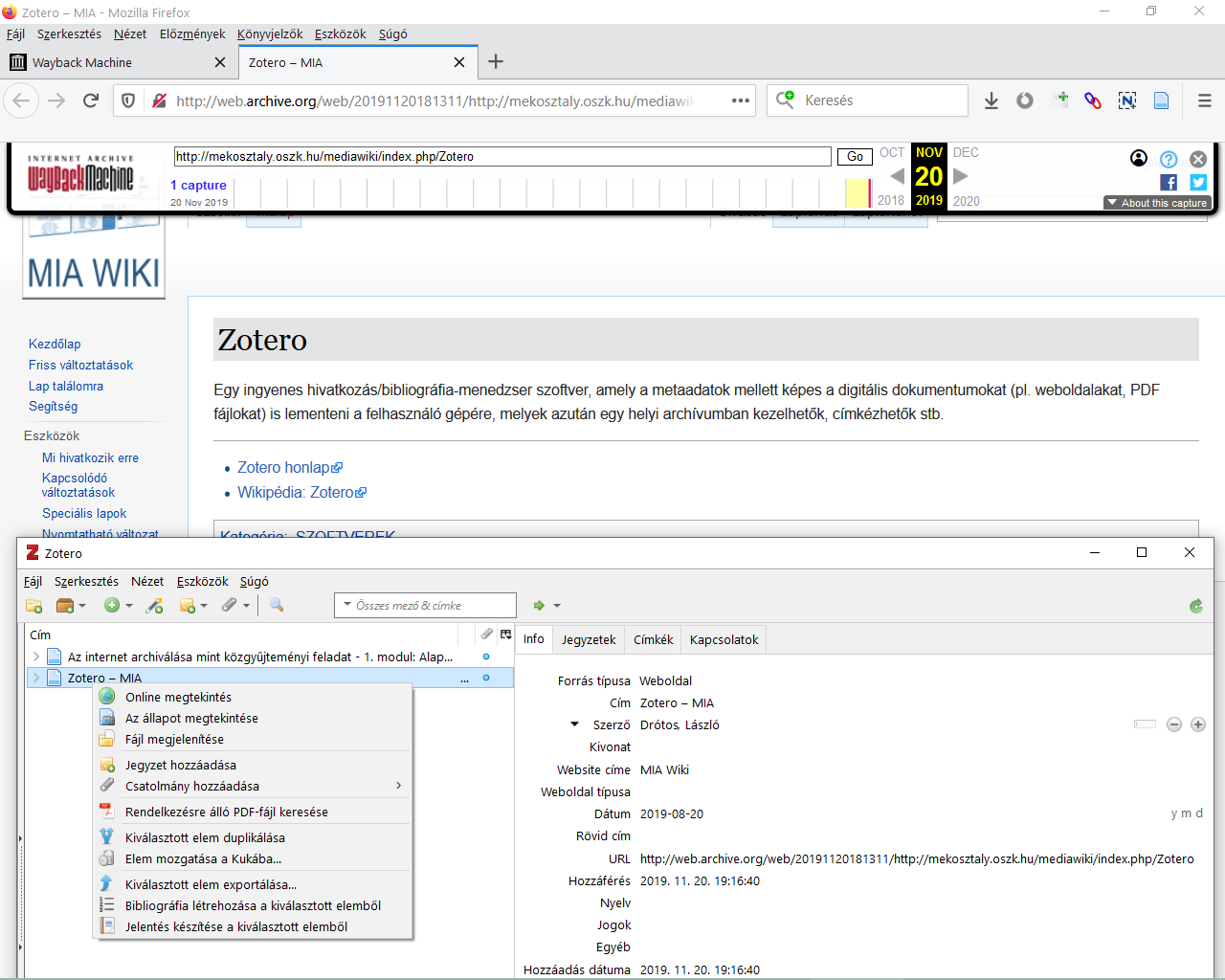
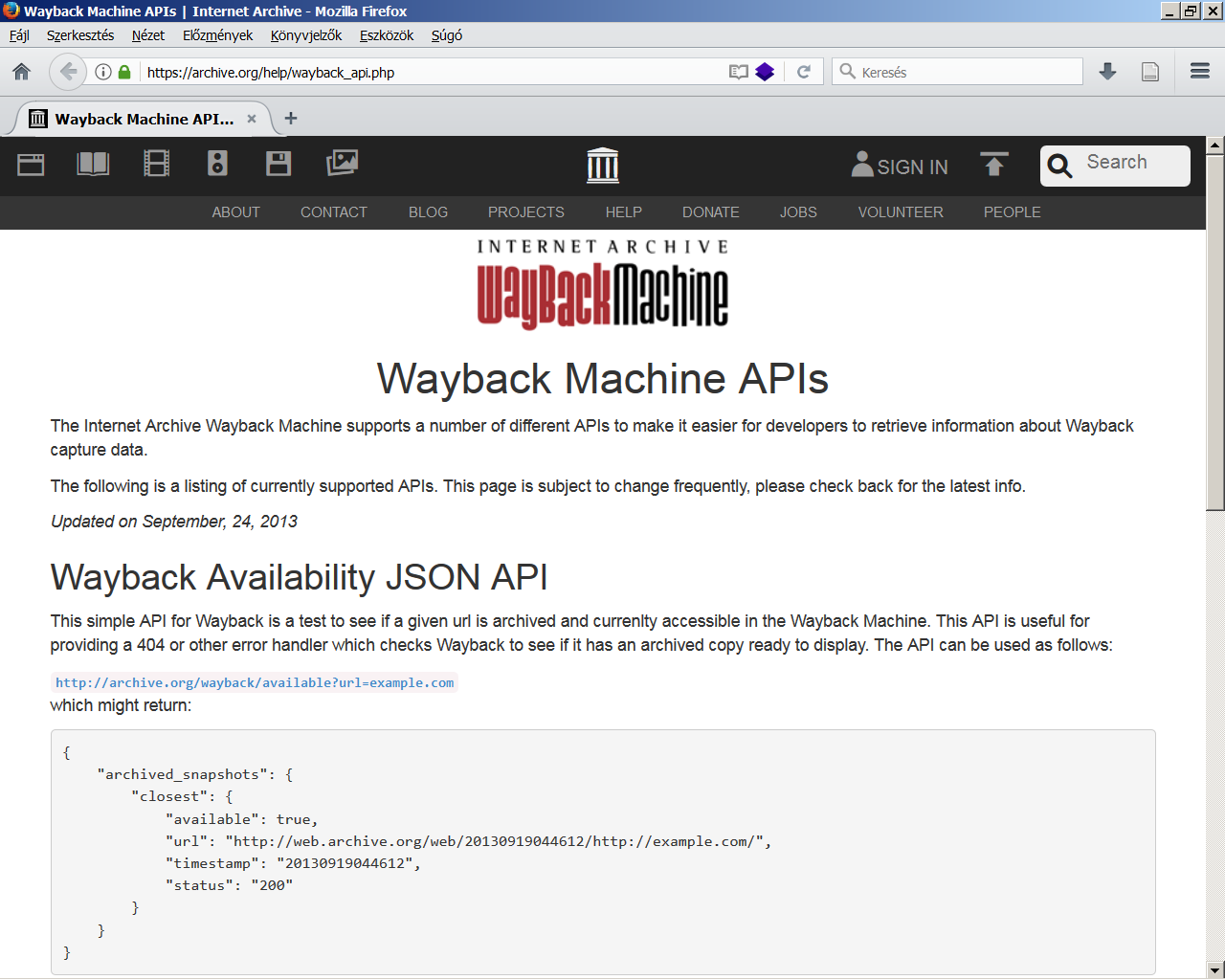
A webarchívumok szerepéről az online forrásokra való stabil hivatkozhatóság megoldásában már az igény esetén archiváló [wiki szócikk] szolgáltatásokat ismertető fejezetben szó esett. Bár ilyenfajta azonnali archiválási funkciót kevés helyen találunk, de legalább annyit érdemes mindenhol megoldani, hogy az archívumba begyűjtött minden weblap és egyéb fontos (pl. PDF) fájl egy stabil, URL-szerű azonosítóval hivatkozható legyen (még akkor is, ha maga a mentett tartalom nem nézhető meg nyilvánosan). Szerencsés, ha ez az azonosító a webarchívum és az eredeti forrás URL címéből, valamint a mentés időpontjából áll össze valamilyen egységes módon, <4.1.1_ia_save_page.png> és érdemes egy linkrövidítő funkciót is beépíteni, amivel a hosszú címek egy publikációban idézhető méretűvé csökkenthetők. Sőt akár magát a teljes hivatkozást is le lehet generálni (különféle hivatkozási stílusok szabályai szerint), amit már csak át kell másolnia vágólapon keresztül a felhasználónak, vagy egy kattintással beemelheti azt a hivatkozáskezelő (pl. Zotero [wiki szócikk]) alkalmazásába. <4.1.1_zotero.png> De egy webarchívumban akár az is megoldható, hogy a weboldalakon belül minden objektumnak (pl. képnek, táblázatnak, beágyazott médiának) egyedi azonosítót generál a rendszer, a linkeket pedig kiegészíti olyan minősítőkkel, amelyek pl. a navigálást vagy az automatikus hivatkozáskészítést segítik [typed links][1]. Ahhoz, hogy az archívumban található tartalom egyes elemei automatizált módon más rendszerekből és alkalmazásokból is megtalálhatók és hivatkozhatók legyenek, egy API-t (alkalmazásprogramozási felületet) szoktak biztosítani a webarchívum fejlesztői. <4.1.1_wayback_api.png>
{kind=link}
{kind=link}
{kind=link}
Az internetes tartalmak gyűjteményei kiváló alapanyagot jelentenek mindenféle adat- és szövegbányászati kutatás számára (betartva közben természetesen a különböző adatvédelmi szabályokat). Az élő webről való tudományos vagy üzleti célú adatgyűjtésnek [web scraping][2] már kiforrott technológiája és jelentős piaca van. <4.1.1_web_scraping.png> A webarchívumoknak viszont időbeli mélységgel is rendelkeznek, ami egy új dimenziót ad a jelen idejű világhálónak és lehetővé teszi kultúránk internetes lenyomatainak trendelemzését, legyen szó a leghétköznapibb dolgokról, vagy a legnagyobb globális problémákról. Az internet történetével és az archivált internetes tartalmakból kinyerhető társadalom-, politika-, gazdaság-, kultúra-, nyelvtörténeti stb. információk kutatásával foglalkozó webhistoriográfia [wiki szócikk] egy kialakulóban levő tudományterület. Egy webarchívum tartalmának tudományos elemzése ugyanakkor nem egyszerű feladat, hiszen hatalmas, csak lazán (hiperlinkekkel) strukturált és minden szempontból nagyon heterogén adathalmazról van szó [big data][3], amiben sokszor nehéz megállapítani egy adat vagy dokumentum eredeti forrását és keletkezési idejét. <4.1.1_common_crawl.png> Ezért mindenféle szűrésnek, tisztításnak és egységesítésnek kell alávetni a kiválasztott részhalmazt, hogy kielemezhető állapotba kerüljön. Egyes archívumoknál kínálnak is ilyen megtisztított, letölthető adathalmazokat, illetve olyan szolgáltatást, hogy megfelelő formátumban és minőségben előkészítik a kutatók számára a kért adatokat. <4.1.1_archive-it_rs.png>
{kind=link}
{kind=link}
{kind=link}
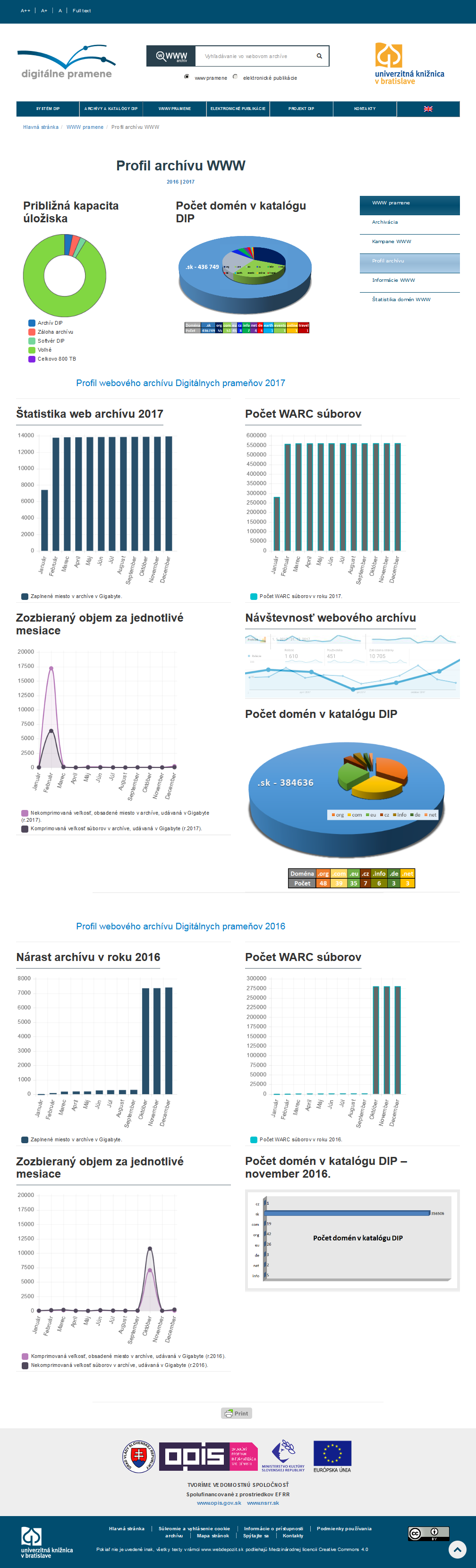
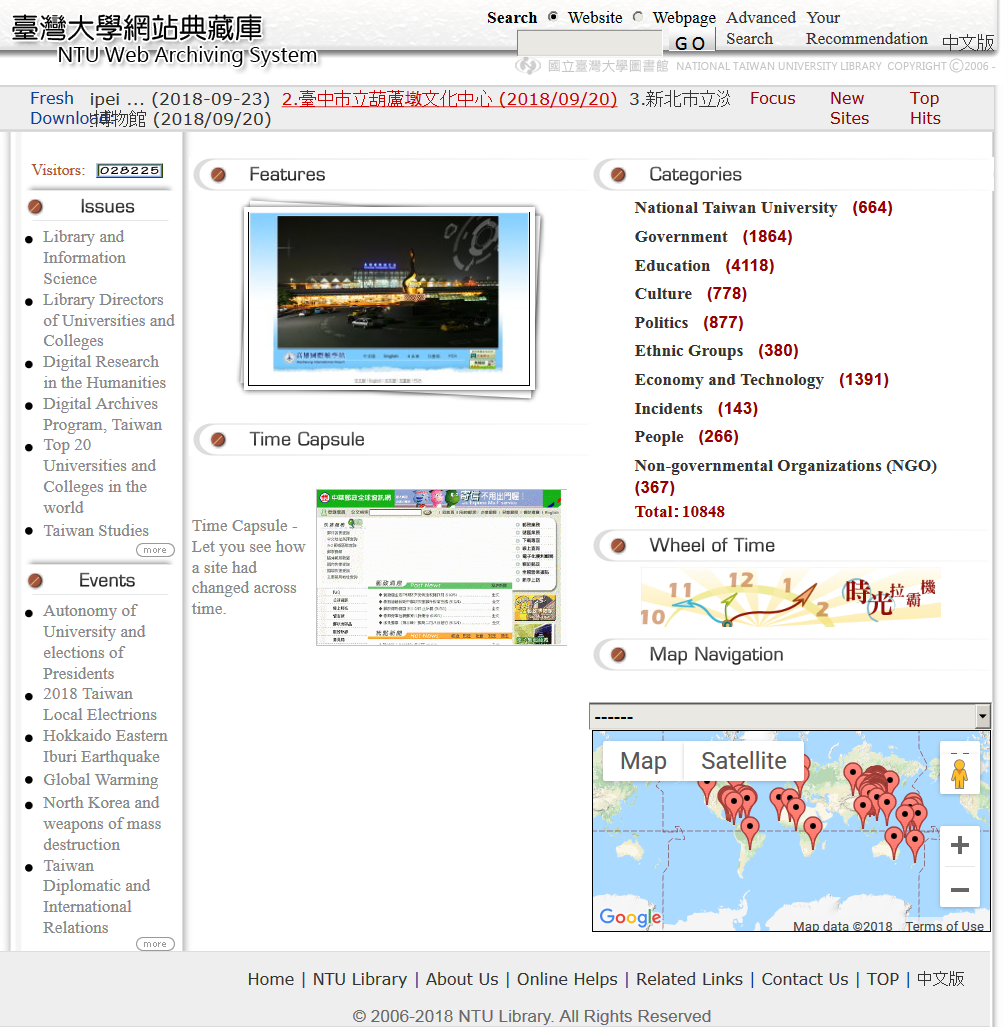
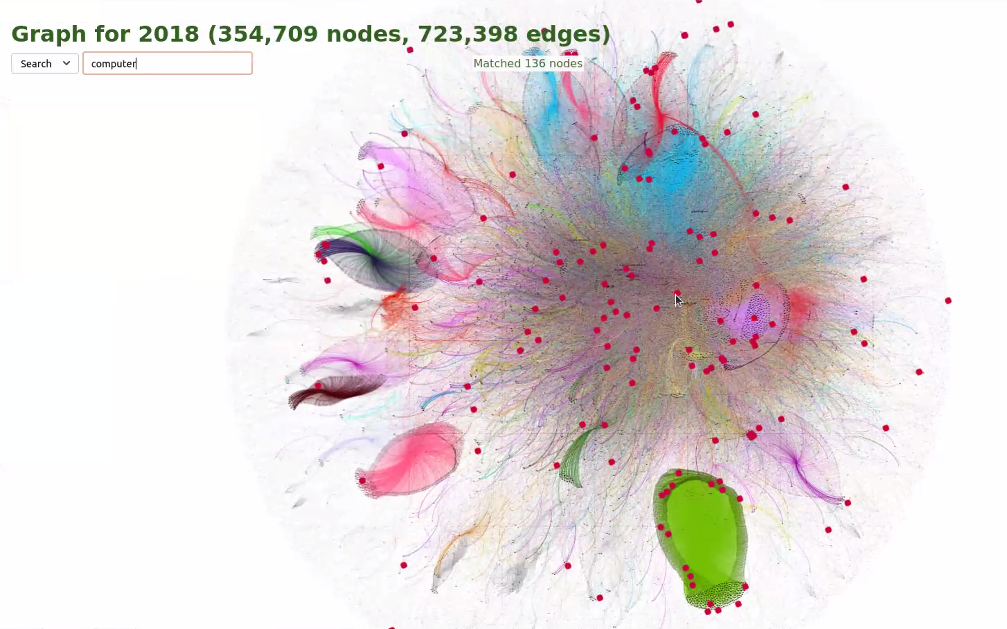
A nagy tömegű adat és weboldal áttekinthető formára alakítását szolgálja a vizualizáció [wiki szócikk] is. Ez segítheti az archívum átlátását (pl. gyarapodási grafikon, fájlformátum és -méret szerinti eloszlási diagram); <4.1.1_webdepozit.png> <4.1.1_elperi.pdf> a böngészést (pl. képernyőfotókból álló animáció, időskálára ill. térképre vetítés); <4.1.1_ntu_was.png> illetve a kapcsolatok és a tartalom ábrázolását (pl. linkgráf, címkefelhő, gyakorisági diagram); <4.1.1_ukwa_visualisation.png> <4.1.1_dan_web.png> vagy egyszerűen csak művészi hatást kelt.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Az IIPC keretében külön munkacsoport foglalkozik a kutatási célú hasznosítással (Research Working Group), melynek egyik jó példája a WARCnet [wiki szócikk]. Ennek a kezdeményezésnek az a célja, hogy olyan projekteket támogasson, melyek az egyes nemzeti domének történetére, azok összehasonlító elemzésére irányulnak, illetve a tematikus archiválási tevékenységek eredményeinek vizsgálatával foglalkoznak.Az eredményeket önálló kiadványsorozatban (WARCnet Papers) és lektorált folyóiratokban közölt cikkek formájában osztják meg a tudományos közösséggel.A projekt eredetileg 2021 végéig tartott volna, de a koronavírus járvány miatt a határidő 2022 végéig hosszabbodott meg. A pénzügyi hátteret dán kutatási források biztosítják, az adminisztráció is az Aarhusi Egyetemen zajlik.
Speciális szolgáltatás lehet a helyreállítás [wiki szócikk], ami jelentheti a véletlen törlés vagy hackertámadás miatt tönkrement weboldalak vagy webhelyrészek rekonstruálását az archívumban levő utolsó másolatból, vagy akár már régen eltűnt honlapok életre keltését pl. valamilyen évforduló alkalmából vagy egy virtuális kiállításhoz. Bár a WARC konténerekből visszaállítani az eredeti fájlrendszert nem egyszerű, de vannak már erre is szoftverek, amelyekkel és némi emberi utószerkesztéssel megoldható a feladat. <4.1.1_wm_downloader.png>
{kind=link}
Egyre több cég szakosodik arra, hogy akár bírósági ügyekben bizonyítékként is elfogadható, hiteles másolatokat szolgáltasson internetes tartalmakról. Ehhez archiváláskor titkosítással, időbélyeggel és digitális aláírással (tanúsítvánnyal) látják el a fájlokat, megakadályozva azok utólagos módosításának lehetőségét. <4.1.1_webpreserver.png> Különösen olyan intézmények (pl. kormányzati szervek, vállalatok) számára fontos az, hogy az online felületeken közzétett digitális tartalmaikat ilyen biztonságos archívumokban tárolják, amelyeknek törvény által előírt kötelességük minden irat és kommunikáció megőrzése adott vagy határozatlan ideig.
{kind=link}
Ajánlott források: 1. MIA Wiki: Hasznosítás, 2. Archive-It Research Services, 3. Yahoo Webscope Program, 4. MirrorWeb, 5. Trevor Thornton: GeoCities Hall of GIFs, 6. Németh Márton: Webarchívum mint a tudományos kutatások tárgya, 7. Tim Sherratt: Jupyter notebooks for web archives
Az előadó linkgyűjteménye: Németh Márton: Webarchívumok hasznosítása, együttműködés módjai a webarchiválás során - hasznos hivatkozások
2. Együttműködési lehetőségek
2.1. Munkamegosztás
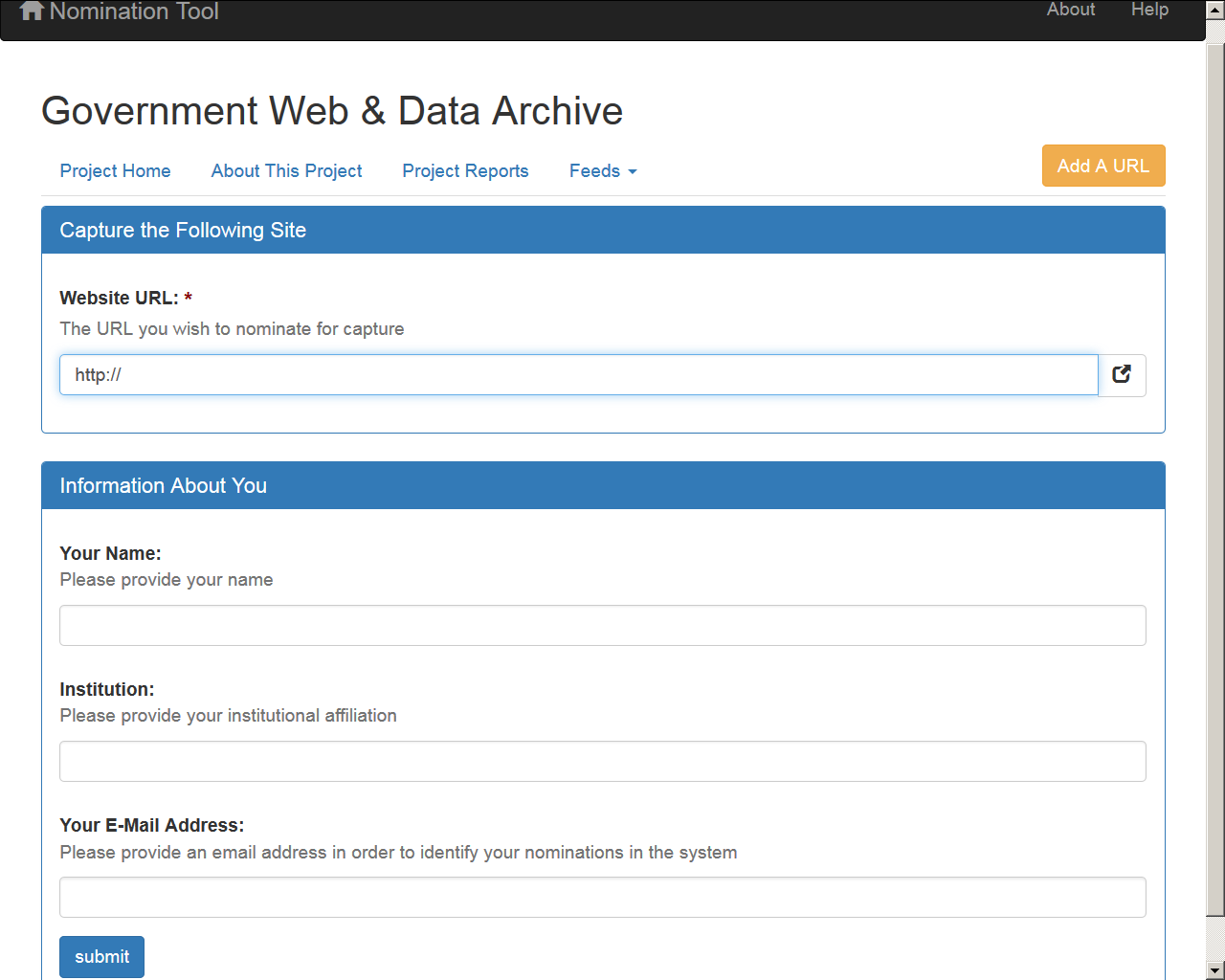
Több országban konzorciális együttműködés keretében folyik a webarchiválás: a résztvevő intézmények elosztják (pl. gyűjtőkörök szerint) a válogatás, a minőségellenőrzés és a metaadatolás munkálatait. <4.2.1_pandora.png> Gyakori az is, hogy az archívumot építő közgyűjtemény az informatikai fejlesztési feladatokat és a műszaki infrastruktúra működtetését egy erre szakosodott kormányzati, egyetemi vagy céges partnerre bízza. A kooperáció egy másik területe az internetszolgáltatók és az online tartalomszolgáltatók megnyerése, hogy segítsék az archívum munkáját azzal, hogy népszerűsítik a webhelyek robot- és archívumbarát kialakítását; az automatikusan nem, ill. nem jól aratható webhelyek esetében valamilyen alternatív megoldást dolgoznak ki az archívum üzemeltetőivel közösen a tartalom eljuttatására; vagy pl. értesítik őket az új vagy a megszűnés előtt álló szolgáltatásokról stb. A domén-szintű aratásokhoz szükség van az adott országdomén alá bejegyzett összes címre, amit a regisztrálást végző szervezet(ek)től szokott valamilyen időközönként megkapni a nemzeti webarchívumot üzemeltető könyvtár vagy egyéb intézmény. A harmadik kört az internethasználók jelentik, akik egyrészt konkrét javaslatokat tudnak tenni egy erre szolgáló űrlapon <4.2.1_nomination.png> és/vagy e-mail címen keresztül, vagy akár a böngészőjükbe beépíthető könyvjelző alkalmazásra (bookmarklet) kattintva, így segítve az archívum munkatársait abban, hogy új vagy kevéssé ismert (mert pl. más országban levő) webhelyekről is tudomást szerezzenek. Különösen hasznos tud lenni a válogatásnak ez a tömegbe való kiszervezése (crowdsourcing) az esemény-alapú archiválásokhoz, amikor rövid idő alatt kell összeszedni a legrelevánsabb online forrásokat. A kollektív tudás indirekt módon is kiaknázható és erre is vannak példák: az olyan helyek, mint a Wikipédia, a Twitter, a könyvjelző megosztó szolgáltatások és a közösségi média egyéb csatornái, felületei jó linkforrások tudnak lenni egy-egy témakör vagy esemény fontos, érdekes, vagy legalábbis leggyakrabban hivatkozott URL címeinek gyűjtéséhez. A felhasználók bevonhatók még például az automatikusan előállított metaadatok javításába, kiegészítésébe, a mentett oldalak megtalálhatóságát elősegítő címkézésbe is, illetve jelezhetik az archiválás során keletkezett hibákat és hiányokat. Magyarországon először a 2019-es Internet Fiesta alatt hirdettünk meg URL-ajánló akciót. A szintén ebben az évben kiírt Közgyűjteményi Digitalizálási Stratégia pályázatba pedig bekerült az OSZK webarchívumával való együttműködés, mint a pályázó könyvtárak által vállalható feladat.
{kind=link}
{kind=link}
Ajánlott források: 1. PANDORA Partners, 2. UNT nomination tool, 3. Webhely archiválási javaslat, 4. Drótos László: A webarchívum és a KDS kapcsolata 5. Visky Ákos László: Gyorsmérleg az OSZK Webarchívum és a KDS-K pályázat nyerteseinek együttműködéséről
2.2. Közös kereshetőség
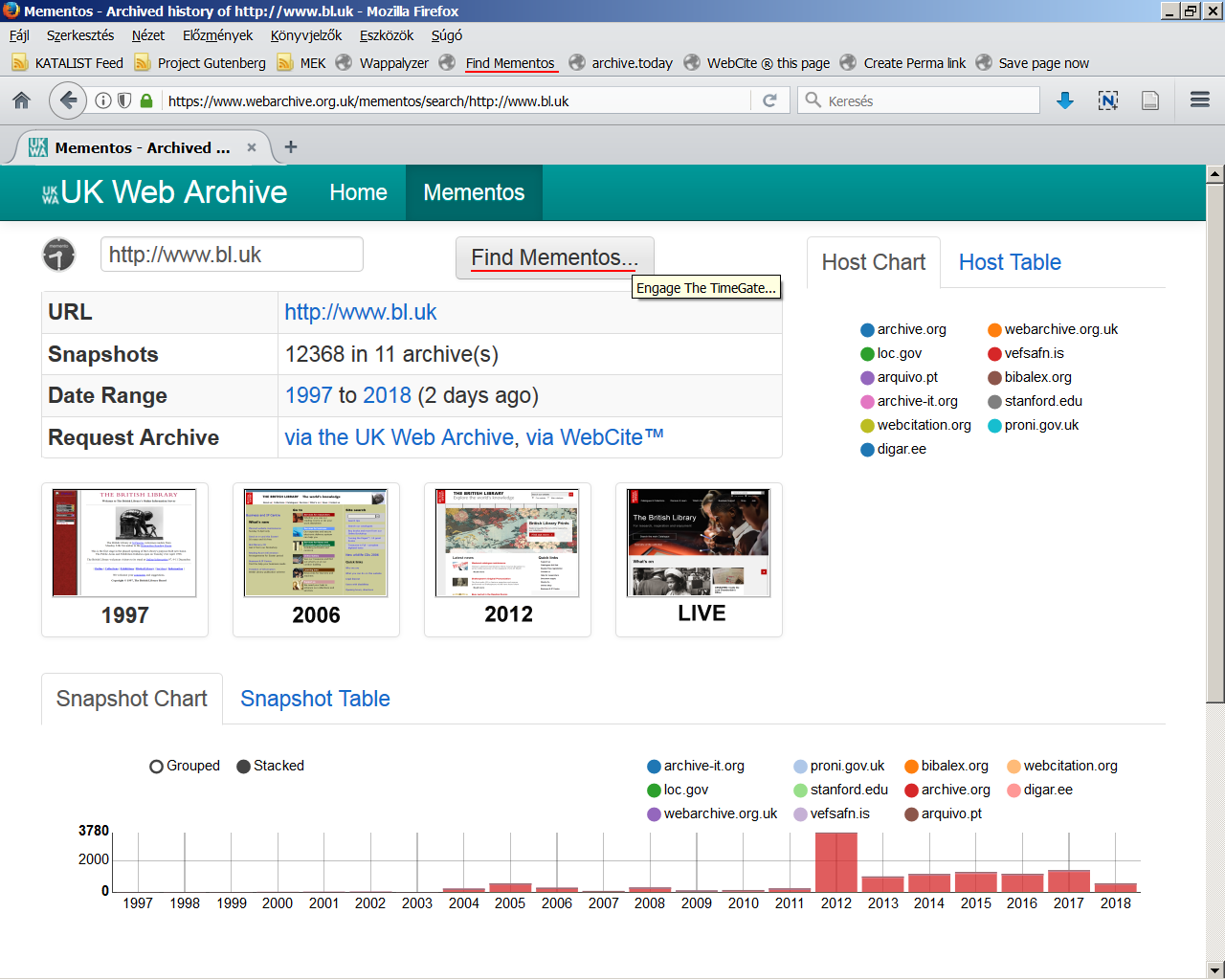
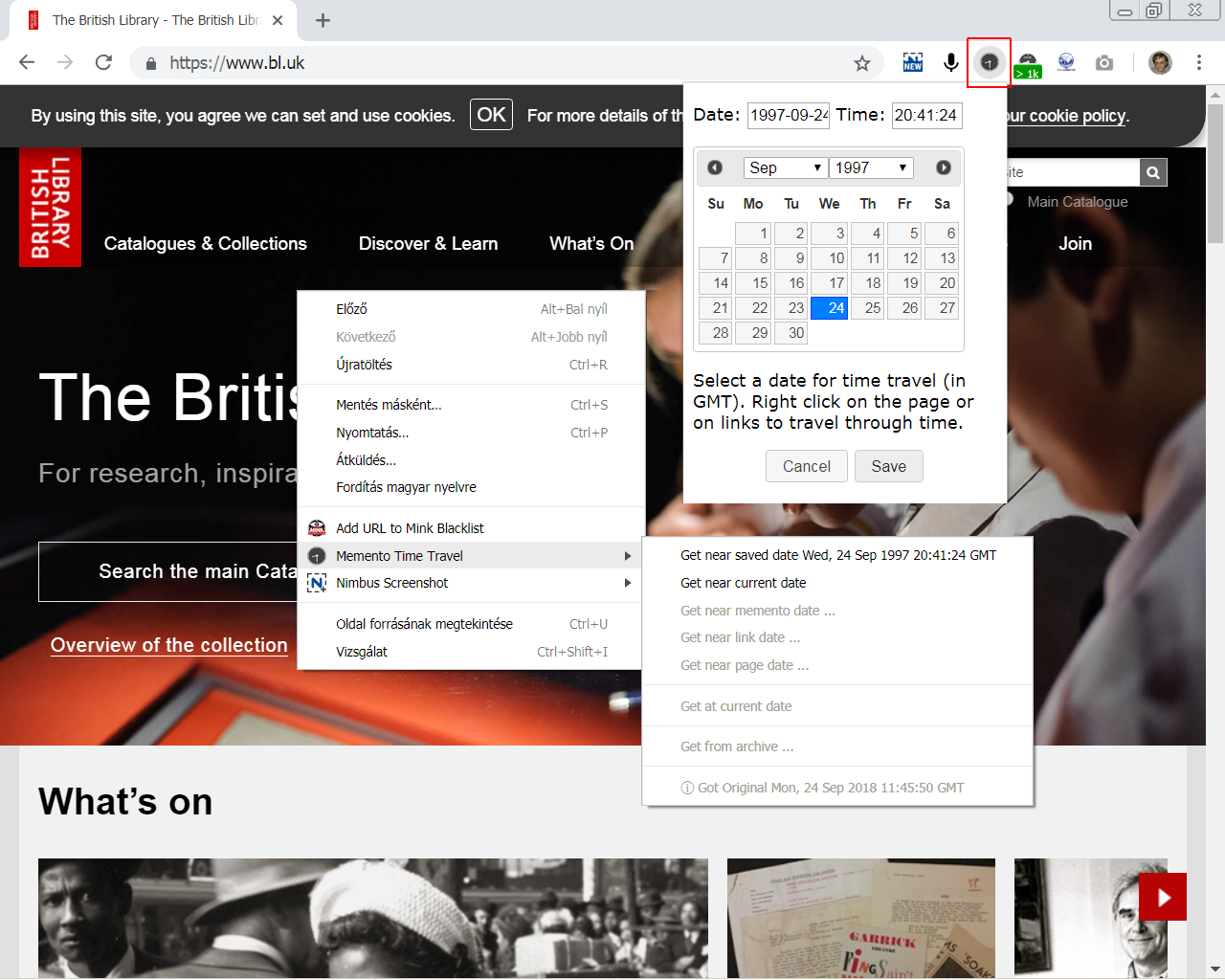
A webarchívumok együttes kereshetősége céljából az amerikai Memento Project <4.2.2_memento.png> keretében a 2010-es évek elején kidolgoztak egy megoldást, ami a webszerverek által használt HTTP protokoll kibővítése egy Accept-Datetime illetve egy Memento-Datetime elemmel. Előbbivel a kliensek (pl. egy webböngésző vagy egy keresőprogram) le tudják kérdezni az archívumot, hogy megvan-e ott egy adott URL címhez tartozó weboldal vagy egyéb fájl adott időpontbeli mentése? Utóbbival pedig az archívum webszervere jelzi a kliens felé, hogy az általa visszaküldött weboldal vagy fájl mikor lett lementve. Ehhez a webszervert ki kell egészíteni egy TimeGate nevű modullal, ami képes ezeket az idődimenziót is tartalmazó HTTP kéréseket és válaszokat kezelni. <4.2.2_memento_tt.pdf> Már most is több online szolgáltatás és szoftver, illetve böngészőbővítmény használja ezt a kibővített protokollt, jelentősen megkönnyítve ezzel az internethasználóknak az élő webről eltűnt oldalak megtalálását, bárhol is archiválták azokat. <4.2.2_mementos1.png> <4.2.2_mementos2.png>
{kind=link}
{kind=link}
{kind=link}
Ajánlott források: 1. Memento Project, 2. Time Travel, 3. Awesome Memento
Összefoglalás:
Ahhoz, hogy egy webarchívum évtizedeken keresztül fennmaradhasson, kell egy stabil intézményi és fenntartói (plusz esetleg szponzori) háttér; egy komolyabb felhasználói bázis, amellyel indokolható az archívum társadalmi hasznossága és amelynek egyes tagjai még fizetni is hajlandóak bizonyos értéknövelt szolgáltatásokért, hozzájárulva így az üzemeltetési és fejlesztési költségekhez; és kell egy minél szélesebb együttműködési hálózat, ami segíti a rohamosan növekvő és eltűnő, technológiailag is rendkívül gyorsan változó online tartalom gyűjtését és feldolgozását, mert az internet megőrzése nem lehet csak egyetlen közgyűjtemény feladata.
Önellenőrző kérdések:
Hogyan tudják segíteni az internetes archívumok a tudományos munkát?
Milyen vizuális megoldásokkal lehet látványossá tenni a webarchívumokban található rengeteg információt?
Mit jelent az, ha egy webszerver támogatja a Memento protokollt?
Ön mivel tudná támogatni egy webarchívum munkáját?
Megoldandó feladatok:
Telepítse a Memento aktív könyvjelzőt a http://www.webarchive.org.uk/mementos/ oldalról! (Ehhez a Nézet vagy a Testreszabás vagy a Beállítások menüpont alatt be kell kapcsolnia a Könyvjelző eszköztárat/Könyvjelzősávot, amennyiben az nem látszik a böngésző felső részén.) Az „Installing the bookmarklet...” feliratú szövegdobozban levő „Find Mementos” linket az egérrel megfogva tegye rá a Könyvjelző eszköztárra/Könyvjelzősávra. Ezután nyissa meg pl. a http://bbc.com oldalt és az eszköztáron/sávon a „Find Mementos” könyvjelzőre kattintva a „Host Table” fül alatt nézze meg, hogy hol és hány mentése van a BBC honlapjának? Próbálja ki azt is, hogy ha a „Host Chart” és a „Snapshot Chart” grafikonoknál kikapcsolja az archive.org szervert (vagyis az Internet Archive-ot), akkor hogyan változik a mentések eloszlása a többi webarchívum között?
Javasoljon megőrzésre érdemes magyar webhelyet a https://forms.office.com/r/Cz3GsHSQEd címen található űrlappal! (Előtte ellenőrizze az ugyaninnen elérhető seed-keresővel, hogy az illető oldal URL-je nem szerepel-e már az OSZK által archivált webhelyek között?)
Az Internet Archive-ra alapozott és sajnos már csak archivált változatban létező http://web.archive.org/web/*/http://webverse.org/ oldalon az „1996”-ra kattintva, majd (a Wayback Machine fejlécét az X-szel bezárva) a 3D térkép tetején pl. a hvg.hu címre rákeresve nézze meg az akkori főbb magyar doméneket. Ezután újra megnyitva vagy frissítve ezt az oldalt, válassza ki „2016”-ot és először fent a Story menüpontra, utána az oldal alján a magyarázó szövegre kattintgatva nézze végig a 2016-os internet egyes főbb csomópontjait. Majd pedig ismét a hvg.hu-ra keresve és a térképbe belenagyítva figyelje meg, hogy melyek az online HVG-hez kapcsolódó (legközelebbi) egyéb domének. Ismételje meg ugyanezt az index.hu és az origo.hu URL címekre is.
A brit webről (.uk domén) 1996 és 2013 között az Internet Archive által készített mentésekben kereső https://www.webarchive.org.uk/shine/graph oldalon a "big data" kifejezés gyakorisági görbéjén a 2009-es időszakon belül találja meg azt a pontot, ahol a kurzor kis körökre vált, majd rákattintva nézze meg, hogy milyen hírforrásokban és milyen szövegkörnyezetben fordult elő ez a két szó. Keresse meg a BBC hírét a találati listában, majd a linket új fülön megnyitva figyelje meg, hogy a mentett cikkben levő képek alatt van egy hibaüzenet. Mi lehet ennek a magyarázata? A grafikont tartalmazó oldalra visszatérve a "big data" helyett írja be ezt a kérdést (az idézőjelekkel és a vesszőkkel együtt): "Jamie Oliver", "Gordon Ramsay", "Nigella Lawson" (majd nyomja meg az Entert). Kattintson a grafikon egyes pontjaira, hogy az adott évből kapjon 100 véletlenszerű találatot. Nézze meg a Wikipédiában, hogy mi történt Gordon Ramsay-vel 2001-ben, amiért ennyire sokat írtak róla akkor?
JEGYZETEK
1 A HTML nyelvben használható link relation attribútummal ellátott hiperhivatkozások összefoglaló neve.
2 Egy crawler segítségével weboldalak begyűjtése, majd ezekből adatok kinyerése automatikus vagy félautomatikus módszerekkel.
3 A hagyományos adatkezelő rendszerekkel nem, vagy nem hatékonyan feldolgozható, igen nagy méretű, komplex és változatos adatállományok összefoglaló neve.

