
1. modul: Alapozó ismeretek
Bevezető gondolatok
Ez a modul az interneten születő és terjedő digitális kultúra legalább részleges megőrzésének fontosságára hívja fel a figyelmet. Megfogalmazza a memóriaintézmények (pl. könyvtárak, levéltárak, múzeumok, audiovizuális archívumok) felelősségét és feladatait ezen a téren. Egy rövid körképet ad a külföldi gyakorlatról és jogi szabályozásról, bemutat néhány fontosabb webarchívumot, valamint ismerteti az Országos Széchényi Könyvtár eddigi eredményeit és jövőbeli terveit. A szakterület elméleti megalapozása céljából különböző szempontok szerint osztályozza az internetarchívumokat.
Célok, megszerezhető kompetenciák:
A modul célja, hogy a tanulóban felkeltse az érdeklődést a digitális születő, a korábbi papír-alapúnál sokkal tünékenyebb kultúra megőrzése iránt, és kialakítson benne egy általános képet a külföldi és hazai internetarchiválási törekvésekről. Továbbá bevezeti azokat a szakkifejezéseket, amelyek ismeretére a későbbi modulok során szükség lesz. A megoldandó feladatok elvégzésével alapszinten lehet megismerni néhány webarchívumot, a bennük való keresést és navigációt.
Szükséges eszközök, források:
Asztali számítógép vagy laptop internet kapcsolattal és webböngészővel.
Feldolgozási idő:
7×45 perc
Témakörök:
Ajánlott irodalom:
Drótos László: Az internet archiválása mint könyvtári feladat.
In: Tudományos és Műszaki Tájékoztatás, 2017. (64. évf.), 7-8. sz.
http://tmt.omikk.bme.hu/tmt/article/view/1025Drótos László - Moldován István: Az OSZK web-archiváló kísérleti (pilot) projektjének eredményei és egy üzemszerűen működő magyar webarchívum terve
In: Könyvtári Figyelő, 2019. (65. évf.) 1. sz.
http://ki2.oszk.hu/kf/2019/04/az-oszk-webarchivalo-kiserleti-pilot-projektjenek-eredmenyei-es-egy-uzemszeruen-mukodo-magyar-webarchivum-terve/Drótos László: Az OSZK webarchívumának újdonságai
In: Könyvtári Figyelő, 2020. (66. évf.), 1. sz.
http://ojs.elte.hu/kf/article/view/1065Németh Márton: A webarchiválás elméletének és gyakorlatának alapelemei
PhD dolgozat, Debreceni Egyetem, 2021.
https://dea.lib.unideb.hu/dea/handle/2437/310638
Kornhoffer Mónika: Internet-archívumok hazánkban és Közép-Európában
In: Felderítő Szemle, 2011. (10. évf.) 3-4. sz. p. 63-78
http://www.knbsz.gov.hu/hu/letoltes/fsz/2011-3-4-2012-1.pdf#page=63Hegyközi Ilona: Hol tart ma a webarchiválás?
In: Könyvtári Figyelő, 2014. (60. évf.), 4. sz.
http://ki.oszk.hu/kf/2015/01/hol-tart-ma-a-webarchivalas/Németh Márton: Nemzetközi körkép a webarchiválás gyakorlatáról
In: Könyvtári Figyelő, 2017. (63. évf.), 4. sz.
http://ki2.oszk.hu/kf/2018/01/nemzetkozi-korkep-a-webarchivalas-gyakorlatarol/Németh Márton: Webarchiválás két szakmai rendezvény tükrében
In: Könyv, Könyvtár, Könyvtáros, 2019. (28. évf.) 6. sz.
http://ki2.oszk.hu/3k/2019/11/webarchivalas-ket-szakmai-rendezveny-tukreben/
1. Újabb sötét középkor fenyeget?
1.1. A digitálisan születő és az interneten terjedő kultúra megőrzésének fontossága
Digitális világunk az egyén és a társadalom életének minden szegmensét áthatja. Az interneten tárolt és azon keresztül közvetített kultúra sokkal változékonyabb és tünékenyebb, mint a korábbi papíralapú. <1.1.1_lostsites.pptx> A megszűnt weboldalakat jelző hibaüzenet [404-es error][1] a legnézettebb online tartalom és sajátos népművészeti ággá vált. <1.1.1_404error.pptx> Ha nem teszünk valamit digitális kultúránk legalább egy részének a hosszú távú fennmaradásáért, akkor egy új dark age jöhet: a jövőből megismerhetetlenek, értelmezhetetlenek lesznek korunk eseményei és folyamatai, amelyek elsősorban vagy már kizárólag a világhálón zajlanak. De az online források instabilitása a jelenben is egyre nagyobb gond például a tudományos hivatkozásoknál, vagy az oktatásba való beépítésüknél. A linkek romlása [link rot][2], illetve a mögöttük levő tartalom megváltozása [content drift][3] megbízhatatlanná teszi a világhálót. Az élő web [live web][4] egy jelen idejű médium. Ahhoz, hogy múltja is legyen, idődimenziót kell adni neki, ami jelenleg úgy oldható meg, hogy egyes részeiről pillanatképeket készítünk és ezeket archiváljuk [memento][5].
Ajánlott források: 1. Wikipedia: Link rot, 2. ArchiveTeam Magyarország - Idővonal, 3. Archive Team: Rescued Sites, 4. Archive Team: Lost Sites, 5. Renny Gleeson: 404, the story of a page not found
Az előadó prezentációja: Moldován István: Az internet archiválása mint közgyűjteményi feladat - Bevezetés
2. Ki őrzi meg az internetet?
2.1. A közgyűjtemények feladata az internetes kultúra megőrzésében
Bár vannak olyan nonprofit szervezetek, mint az Internet Archive <1.2.1_ia.png>, önkéntes szerveződések, mint az Archive Team <1.2.1_at.png>, továbbá online tartalmak lementésére és tárolására szakosodott cégek [web archiving service], és az is előfordul, hogy maga a tartalmat létrehozó vagy azt szolgáltató intézmény/szervezet/vállalat őrzi meg az élő webről lekerülő anyagot, de válogatott és rendszerezett, hosszú távú, gondozott webarchívumokat leginkább a közgyűjtemények tudnak működtetni, melyeknek amúgy is évszázados feladatuk a kulturális örökség megőrzése és a hozzáférés biztosítása. Ebben a tevékenységben előnyös tud lenni, ha együttműködnek más típusú szervezetekkel és cégekkel, mert a digitális univerzum mind méretében, mint pedig változékonyságában akkora kihívást jelent archiválhatóság és szolgáltatható állapotban tartás szempontjából, amivel ezek a memóriaintézmények korábban nem találkoztak. És természetesen emiatt érdemes egymás közt is kooperációkat kiépíteni, megosztani a feladatot a különböző típusú könyvtárak [webrary],[6] a levéltárak, valamint a múzeumok között. Nem véletlen tehát, hogy több országban konzorciumok keretében végzik ezt a tevékenységet, erre a feladatra dedikált szakemberekkel [web curator][7].
{kind=link}
{kind=link}
Ajánlott források: 1. UNESCO Charta a digitális örökség védelméről, 2. Drótos László - Németh Márton: Webmúzeum, webkönyvtár, weblevéltár
2.2. Az OSZK feladata és eddigi eredményei
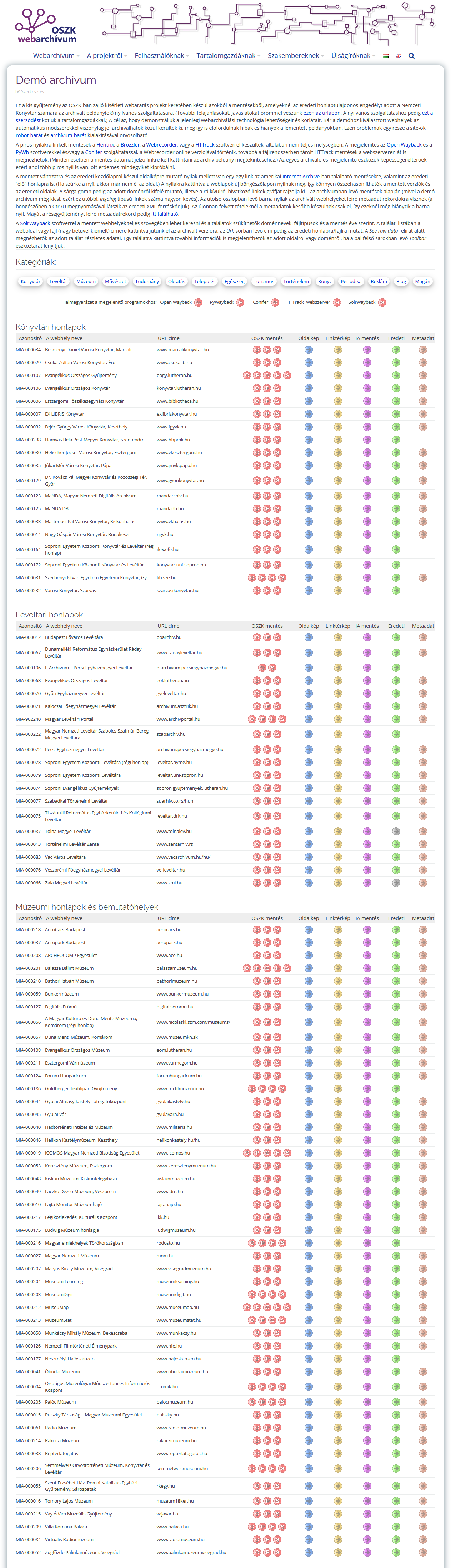
Hazánkban meglehetősen későn, 2006-ban (több mint 10 évvel a web magyarországi megjelenése után) született az első elképzelés a nemzeti könyvtárban a Magyar Internet Archívum (MIA) létrehozására, de további 10 évet kellett várni, mire megteremtődtek a feltételek, hogy legalább kísérleti jelleggel elinduljon egy projekt a webarchiválás területének kutatása és egy üzemszerűen működő, fenntartható archívum létrehozása céljából. (A digitálisan született egyedi dokumentumok gyűjtése viszont már jóval régebb óta folyik az OSZK-ban a MEK, az EPA és a DKA szolgáltatások keretében, így ezek tapasztalatai hasznosíthatók.) A webarchívum 2020-tól már üzemszerűen működik, bár még mindig jelentős a kutatási-fejlesztési tevékenység aránya is. A webarchivum.oszk.hu honlapon <1.2.2_mia.png> megtalálhatók az aktuális hírek, a témához kapcsolódó publikációk, az immár rendszeres őszi workshopok előadásai, egy wiki és egy levelezőcsoport, valamint egy nyilvános demó archívum, a zárt gyűjtemény metadatkeresője és az egyes aratásokról készült statisztikák <1.2.2_demo.png> A cél az lenne, hogy az Országos Széchényi Könyvtár által fenntartott infrastruktúrán és egy kidolgozott know-how alapján minél többen kapcsolódjanak be intézményi ill. egyéni szinten a magyar webtér értékes részeinek kiválogatásába, lementésébe, metaadatokkal való ellátásába és az archívumra épülő szolgáltatások kialakításába. Annak illusztrálására, hogy a webarchiválás hogyan építhető be a könyvtári szolgáltatásokba, a 2019-es Közgyűjteményi Digitalizálási Stratégia pályázat keretében a II. Rákóczi Ferenc Emlékév alkalmából elkészült egy mintaalkalmazás, amely a webarchívum más digitális gyűjteményekkel való integrálásának lehetőségét mutatja be.
{kind=link}
{kind=link}
Ajánlott források: 1. Drótos László: Mi a MIA?, 2. „404 Not Found - Ki őrzi meg az internetet?” workshop, 3. Németh Márton: Az OSZK Webarchívum új honlapjának felépítése és szolgáltatásai
2.3. Az online digitális tartalmak megőrzésére vonatkozó törvényi szabályozás
Az egyes országokban különböző módon szabályozzák (vagy nem szabályozzák) a tartalomszolgáltatók és a könyvtárak, levéltárak jogait és kötelességeit az interneten nyilvánosan közzétett tartalmak megőrzésével kapcsolatban. Van, ahol a köteles példányra vonatkozó vagy más könyvtári/levéltári törvényben egészen részletesen definiálják a gyűjtőkört, valamint a begyűjtés és szolgáltatás/hozzáférés szabályait, sőt akár olyan kitételeket is tartalmazhat a jogszabály, hogy ha egy webanyag nem tölthető le automatikus módszerekkel, akkor annak az archívumba való beküldéséről a tartalom tulajdonosának kell gondoskodnia, és az esetleges plusz költségeket is neki kell kifizetnie. Arra is van példa, hogy a kormányzati intézményeket kötelezik arra, hogy a weboldalaiknak, illetve az azokon közzétett dokumentumoknak akkor is nyilvánosan elérhetőeknek kell maradniuk, amikor már érvényüket vesztve lekerülnek az eredeti webszerverről, ezért ilyenkor pl. a parlamenti könyvtár vagy a nemzeti levéltár webarchívuma veszi át őket. Néhány országban külön szabályozzák és külön gyűjtik (pl. a nemzeti audiovizuális archívumban) az internetről letölthető ill. az interneten keresztül sugárzott video- és hanganyagokat, amelyek archiválásával a legtöbb könyvtár és levéltár nem, vagy csak kis mértékben foglalkozik. Ahol nincsen kellően részletes szabályozás, ott sokszor a köteles példány törvény általános rendelkezései, illetőleg az elektronikus dokumentumokra vonatkozó pontjai alapján végzik a webarchiválást a nemzeti könyvtárak. Magyarországon több mint két éves előkészítő munka eredményeként 2020-ban előbb a kulturális törvénybe került be az OSZK feladatai közé a webarchiválás, majd egy kormányrendelet részletesebben is szabályozta ezt a tevékenységet. Ami a hozzáférést illeti, ezen a téren is vegyes a kép: vagy egy sötét archívumba [dark archive][8] kerül a lementett tartalom, amit legfeljebb csak kutatók használhatnak indokolt esetben; vagy csak helyben, illetve zárt könyvtári hálózaton, esetleg a partnerintézményeknél – erre a célra dedikált, letöltési lehetőség nélküli – gépeken lehet hozzáférni; de arra is van példa, hogy minden olyan webhely mementói nyilvánosan elérhetők az interneten, amelyeknek a tartalomgazdái ehhez hozzájárultak, vagy ez ellen nem emeltek kifogást [opt-out][9]. A magyar szabályozás szerint a kormányzat és az önkormányzatok, valamint az általuk fenntartott intézmények és a költségvetési támogatás igénybevételével létrehozott webhelyek esetében nem kell engedély a webarchívumban való nyilvános szolgáltatásohoz. Egyéb esetekben pedig szerződést köt az OSZK a tartalomtulajdonosokkal.
Ajánlott források: 1. Ludmila Cerbová: A cseh web és a kötelespéldány-rendelet, 2. Németh Márton: Netarkivet.dk - dán netarchívum: gyűjtőkör és szervezeti keretek, 3. Németh Márton: Webarchiválás Észtországban 4. Németh Márton: A nemzeti webarchívum és a helyi NIC (Network Information Center) együttműködése néhány európai országban 5. IIPC honlap: Legal deposit
3. Milyenek az internetarchívumok?
3.1. Internetes tartalmak archiválási módszerei és az archívumok fajtái
Az internetes tartalmak archívumait többféle szempont szerint is csoportosíthatjuk. A begyűjtés történhet szoftveres robottal [crawler][10] való aratással [harvest][11], letöltő alkalmazással, online beküldéssel, vagy akár offline beadással is. Az első két módszernél egy kliens program kéri le a szerverről a tartalmat [client-side web archiving], a harmadiknál a szerver maga küldi azt be az archívumba valamilyen előre egyeztetett megoldással [server-side web archiving] [transaction-based web archiving], míg a negyediknél emberi közreműködéssel, pl. merevlemezen vagy memóriakártyán szállítva jut el az anyag az archívumba. Az archivált tartalom tárolására is több megoldás van: fájlrendszerbe mentés, archív állományba mentés, egységes formátumba mentés, adatbázisba mentés. A gyűjtőkör lehet szelektív [focused crawl]: tágabb vagy szűkebb témakörök, események, internetes műfajok; vagy pedig teljes körű [broad crawl]: világ- vagy világrész-méretű, nemzeti szintű, valamilyen felsőbb domén szintű. Az archiváló kiléte és az archiválás célja szerint megkülönböztetünk magán, céges, intézményi vagy szervezeti, valamint országos vagy nemzeti archívumokat. Végül pedig az idődimenzió alapján is osztályozhatjuk őket: beszélhetünk ismétlődő mentésekből építkező és minden korábbi állapotot hosszú távon megőrző gyűjteményekről; ismétlődő mentésekre alapozott, de csak az utolsó állapotot tároló rendszerekről; valamint kisebb egyedi [micro archiving] vagy alkalmi mentésekről [archive-on-demand] (pl. a stabil hivatkozhatóság céljából). A tartalom lementése természetesen csak egy, és nem is a legelső fázisa a nagyobb webarchívumok munkafolyamatainak: megelőzi egy válogatási és (esetleg) engedélykérési tevékenység, majd az archiválás után a mentett tartalom minőségellenőrzése és szolgáltatható állapotba hozása (pl. hibajavítás, metaadatolás, indexelés) következik. Mindezekről a következő modulokban részletesen is szó lesz. <1.3.1_work_flow.pptx> <1.3.1_work_flow.png>
{kind=link}
Ajánlott forrás: MIA Wiki: Archívumtípusok
3.2. Külföldi projektek, külföldi webarchívumok
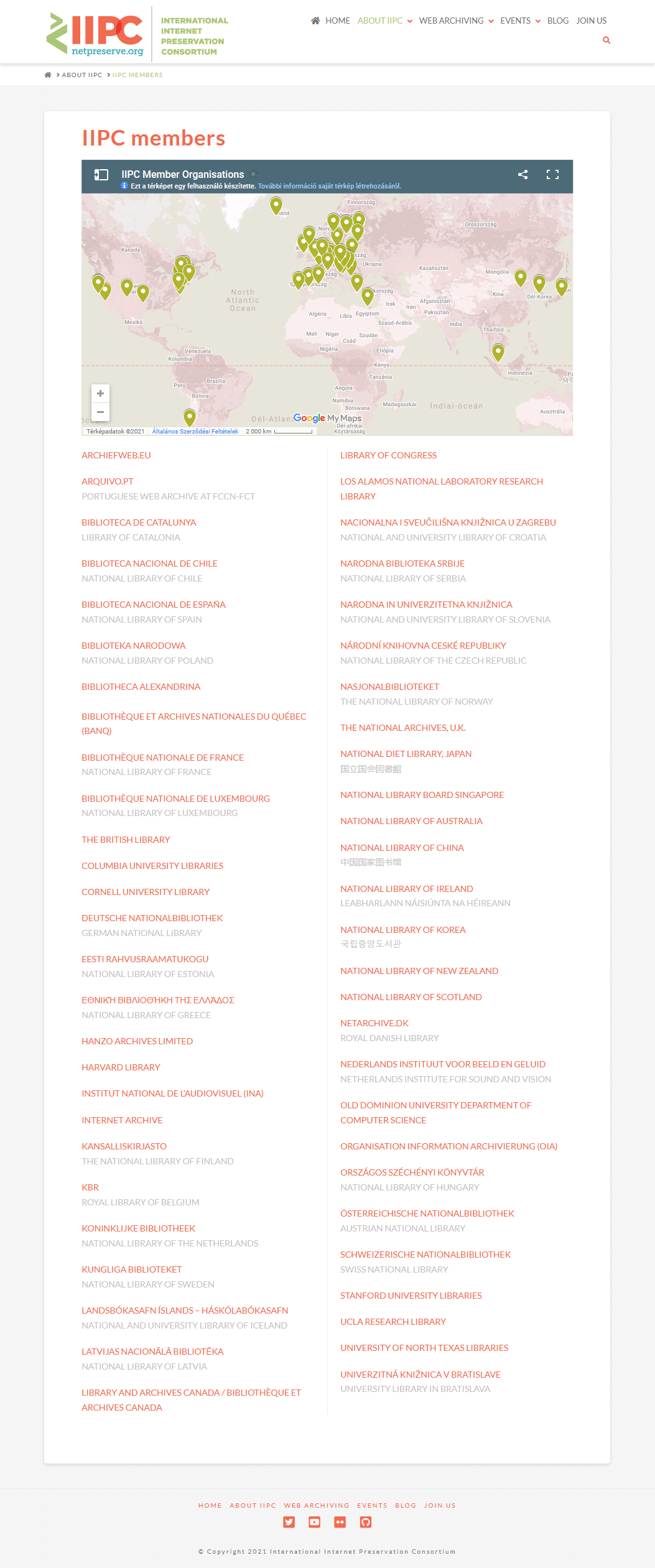
Az online világ kezdeti tartalomszolgáltatásaiból (pl. BBS, WAIS, Gopher) nem sok minden maradt meg, de a World Wide Web első publikus webszervere (restaurálás után) még mindig megnézhető az info.cern.ch címen. <1.3.2_cern.png> Négy évvel ennek megszületése után, 1996-ban megalakult az Internet Archive nevű non-profit szervezet <1.3.2_ia_3d>, azzal a céllal, hogy létrehozza a digitális világ alexandriai könyvtárát, egyebek mellett mára már 500 milliárdnál is több lementett weboldallal, melyek a Wayback Machine <1.3.2_wbm.png> szolgáltatásán keresztül úgy böngészhetők, mintha az élő webet használnánk. <1.3.2_wayback_machine.mp4> Azóta sorra indultak el további webarchívumok és egyéb, az internetes tartalmak megőrzésével kapcsolatos projektek könyvtárakban, egyetemeken, kutatóintézetekben stb. Ezek egy része eleve csak korlátozott időre szólt, másokat pedig egy idő után újragondoltak és -terveztek, így már több második-generációs webarchívummal is lehet találkozni. Jelenleg mintegy 40 nemzeti webarchívum létezik harmincegynéhány országban (mert egyes helyeken a nagyobb nemzetiségeknek külön archívumuk van). Ezek közül érdemes kiemelni és kipróbálni a brit <1.3.2_ukwa.mp4>, a dán, a portugál, a holland, a cseh, a szlovák, az amerikai és az ausztrál szolgáltatásokat. <1.3.2_pandora.mp4> Az internet-archiváló projekteket az International Internet Preservation Consortium (IIPC) nevű nemzetközi szervezet <1.3.2_iipc.png> fogja össze 2003 óta, melynek már több mint 45 országból vannak tagjai. 2018 januárjában magyar részről az OSZK is csatlakozott az IIPC-hez.
{kind=link}
{kind=link}
{kind=link}
Ajánlott források: 1. MIA Wiki: Projektek, 2. Wikipedia: List of Web archiving initiatives, 3. IIPC members
Az előadó linkgyűjteménye: Németh Márton: Hasznos linkek a külföldi webarchiválási projektek bemutatásához
Összefoglalás:
Digitális kultúránk megőrzésében a közgyűjteményeknek is komoly felelőssége van. Az első webarchívumok a kilencvenes évek második felében indultak, azóta már jó néhány projekt szerveződött erre a feladatra, melyek többféle technikával, különböző gyűjtőkörrel és eltérő jogszabályi háttérrel dolgoznak. Az OSZK 2017 elején indított egy projektet a magyar webarchívum megteremtése céljából és egy évvel később belépett az IIPC szervezetbe.
Önellenőrző kérdések: ![]()
Soroljon fel néhány érvet amellett, hogy miért lehet szükség online tartalmak megőrzésére, és hogy miért kell ebben a közgyűjteményeknek is részt venniük?
Mit jelent a szelektív aratás?
Milyen módon lehet egy lementett weboldalra rákeresni a Wayback Machine-nal?
Melyik ország nemzeti könyvtára kezdeményezte az IIPC megalapítását és mivel foglalkozik ez a konzorcium?
Szabályozza-e a webarchiválást a jelenleg érvényes magyar köteles példány rendelet?
Megoldandó feladatok:
Keresse meg munkahelye honlapjának egyik régebbi (viszonylag) jól sikerült mentését az Internet Archive-ban, majd a Wayback Machine fejlécében levő „About this capture” gombra kattintva nézze meg, hogy a nyitóoldal egyes elemeinek mentési időpontja mennyivel tér el plusz vagy mínusz irányban a kiválasztott dátumtól.
A Wayback Machine-nek ezt a sajátosságát úgy hívják szaknyelven, hogy temporal inconsistency. Melyik szócikkben fordul elő ez a fogalom a MIA Wikiben?
Keressen rá a Rákóczi Emlékév Archívum részletes keresőjével a "rendezvény" tárgyszóra. Majd a találatokat szűkítse le egy további feltétel megadásával a nyilvánosan hozzáférhető státuszúakra. Nézzen meg néhány találatot, köztük olyat is, amelyhez digitális videó is tartozik. Hasonlítsa össze az OSZK archívumában levő kétféle megjelenítőt az Internet Archive Wayback Machine-jával, hogy melyikben hogyan jelenik meg ugyanaz a lementett weboldal vagy Youtube videó.
A Pandora archívumban a People & Culture / Ethnic Communities & Heritage kategória alatt keresse meg az ausztráliai Victoria államban élő magyar közösség (Hungarian Community of Victoria) 2000-ben archivált weblapját, és a rajta található copyright információ, valamint az Internet Archive-ban levő későbbi mentések alapján próbálja megbecsülni, hogy mettől meddig létezhetett ez a honlap?
Próbáljon ki régi böngésző-emulátorokat! Az https://line-mode.cern.ch/ címen a világ első honlapjának néhány oldala nézhető meg a korabeli, még nem grafikus kliens szimulátorával a Launch... gombra kattintva. (A linkek a sorszámok begépelésével nyithatók meg, a visszalépéshez a Back szót kell begépelni, lapozni pedig az Enter-rel lehet.) A http://www.dejavu.org/emulator.htm szolgáltatással a Mosaic, a Netscape és az Internet Explorer korai verzióival nézhetünk meg pár mintaoldalt (mindegyiknél csak az első 1-2 link működik sajnos). Az Internet Archive-val összekötött https://oldweb.today oldalon pedig a Mac OS alatt futó Navigator 4-et és a Windows-os IA 6-ot érdemes kipróbálni, URL-nek a http://ikalauz.hu címet megadva, majd a "b@rangolás" menüpont alatt elolvasni néhány kilencvenes évekbeli webhely ismertetőjét. (A virtuális gépből az egérkurzort az Esc gomb megnyomásával lehet visszakapni.)
JEGYZETEK
1 A webszerver által visszaadott hibakód, amikor nem találja a böngésző által kért fájlt.
2 Az internetes hivatkozások mögül eltűnő tartalom problémája.
3 Az internetes hivatkozások mögött megváltozó tartalom problémája.
4 A jelen időpillanatban a weben levő tartalom.
5 Egy webes tartalom elmentett változata.
6 Könyvtári gyűjtemény jellegű webarchívum.
7 Webarchívumot gondozó szakember.
8 A közönség számára semmilyen formában nem hozzáférhető archívum.
9 Eltávolítási lehetőség egy archívumból vagy nyilvántartásból.
10 A weboldalakban levő linkeket követő szoftver.
11 Webtartalmak tömeges letöltése a linkek követésével.

